
PPOL 6801 - Text as Data - Computational Linguistics
Week 1: Introduction, Logistics and R
Professor: Tiago Ventura
Welcome to Text-as-Data!
Outline
Motivation for Computational Linguistics
Digital information age
Principles of Computational Linguistics.
What this course is not.
Examples of models and applications for this course
Introductions
Class Logistics ( + 10 min for you to read through the syllabus)
Q&A
Introduction to R/RStudio
Motivation
For many years, social scientists have used text in their empirical analysis:
Close reading of documents.
Qualitative Analysis of interviews
Hand-Coded content analysis
In the past 20 years, we have been going through a technological revolution:
Consolidation of digital storage vs analogical
Internet: Production of textual information increased
The capacity to store, access and share this large volume of data also increased.
At the same time, the cost of accessing large computing power reduced… think about your laptops…
And even powerful computational models (that do not fit in your laptop) became easily accessible.
Examples of Textual Data
Official Documents: Congressional Speeches, Bills, Press Releases, Transcripts, from all over the world!!

The internet: News, Comments, Blogs, etc…

Genarative AI

What is Text-as-Data?
TaD: focuses on using text as a form of data to make inferences about the world around us, such as human behavior
This class covers:
Computational methods to process and analyze text at scale (Data Science/NLP Tools)
Many applications showing how we can use text to answer social science problems and test social science theories. (Applied Social Science)
Bridge the gap between cutting-edge NLP and meaningful, interpretable research
Do I need an entire course for this? Aren’t my stats/DS classed enough?
Challenges I: Text is an unstructure data source
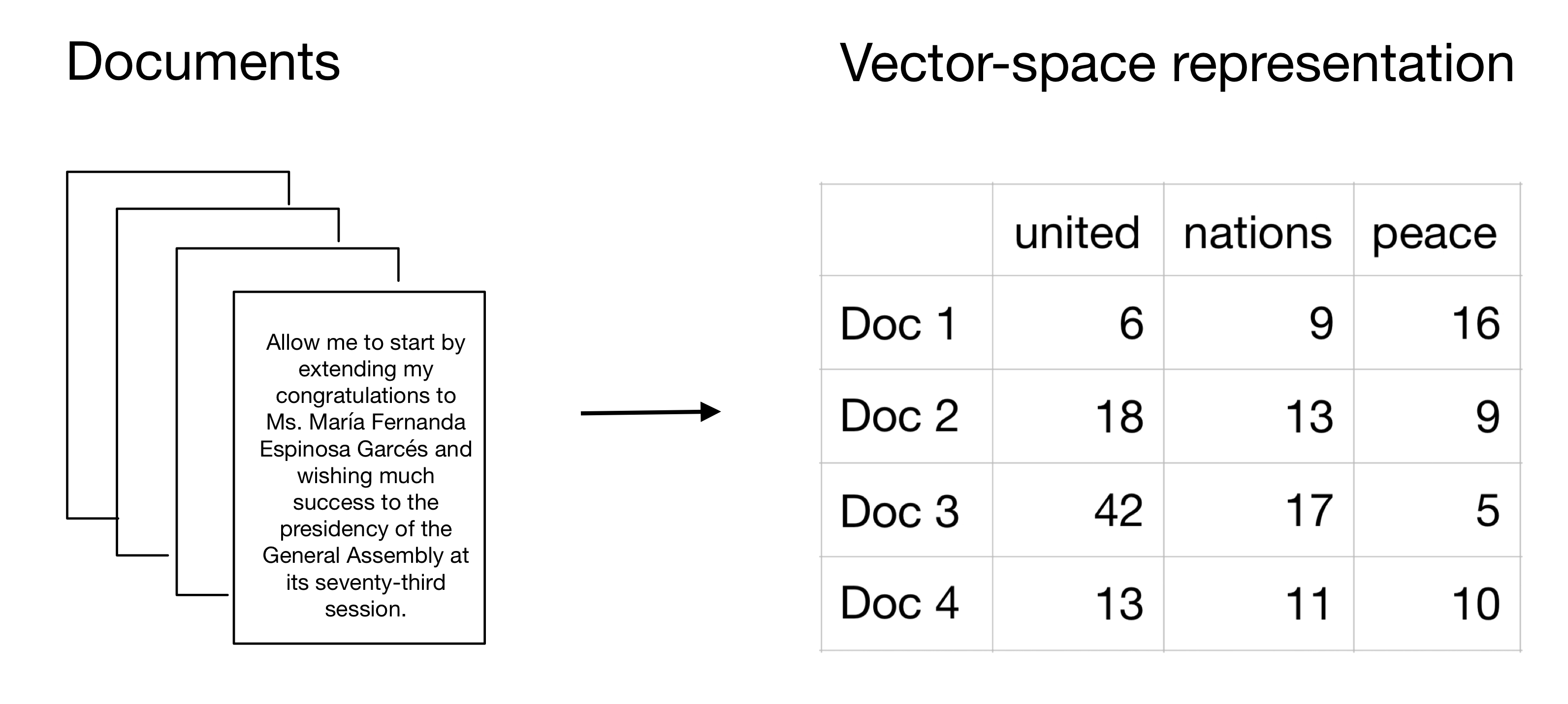
Challenge II: Text is High Dimensional
From Gentzkow et al 2017:
sample of documents, each \(n_L\) words long, drawn from vocabulary of \(n_V\) words.
The unique representation of each document has dimension \(n_{V}^{n_L}\) .
- e.g., a sample of 30-word (\(n_L\)) Twitter messages using only the one thousand most common words in the English language
- Unique Representation: 1000^30 (1000 * 1000 * ….. * 1000)
- As a simplified matrix: \(M^{1000}_{30}\)
- And this matrix will be really sparse!
Most of what you learned in statistics so far does not equip you to deal with large and sparse data
Challenge III: Working in the Latent Space
When working with text, we aim to make an inferences about a latent variable
Latent variable: we cannot observe directly but try to identify with statistical and theoretical assumptions.
Examples: ideology, sentiment, political stance, propensity of someone to turnout
Quite different than asking direct questions via surveys or using macro economic variables…
In text, we only observe the words. Much harder to identify the latent concepts.
Overview of TAD Methods
Descriptive inference: how to convert text to matrices, vector space model, bag-of-words, dissimilarity measures, diversity, complexity, style.
Supervised techniques: dictionaries, classication, scaling, machine learning approaches.
Unsupervised techniques: clustering, topic models, embeddings.
Generative AI: Word embeddings and Large Language Models.
- Generative AI will actually be pretty much half of this course!
Some cool TaD applications
Measure text-reuse across thousands of bills from U.S. state legislatures
Estimate levels of toxicity of comments from stremming chats platforms during political debates
Measure how out-group negative makes things go viral on social media
Estimate ideological positions using who a user follows on Twitter, what a user share on social media, political manifestos, or just asking ChatGPT to pair-wise compare politicians
Use Generative AI to create synthetic data, even survey responses
What this class in not about it…
Data acquisition: no scrapping in class. Assume you have learned already.
- I can share code for those who haven’t.
Regular expressions and basic text manipulation.
CS Stuff: machine translation, OCR, POS, entity recognition.
- Most NLP/CS will focus on developing new algorithms, information retrievel and purely better measurements.
- in a productive dialogue with NLP, we will focus on using text for social science research
- theoretically driven discovery and measurement
- integration with social science problems + tabular data.
Again: Welcome to Text-as-Data!!
Introductions
Professor Tiago Ventura (he/him)
- Assistant Professor at McCourt School.
- Political Science Ph.D.
- Postdoc at Center for Social Media and Politics - NYU.
- Researcher at Twitter.
My Research: Effects of technology in politics + applications of computational models to social science:
- Global Social Media Deactivation.
- Effects of WhatsApp Usage on Elections in the Global South.
- Developing a data donation pipeline for WhatsApp data.
- Measuring Humanness vs AI-Generated Content on Social Media.
- Using LLMs to augment web-browsing data with synthetic data
Outside of work, I enjoy watching soccer, reading sci-fi and running
Your turn!
Name & pronouns
Why are you taking this course?
Your experience (if any) working with text
Your favorite place in DC (restaurant, park, bar, brewery, bakery, you call it!)
Let’s take a break!
Read the syllabus!
10:00
Class Logistics
Weekly Schedule
| Week | Date | Topic |
|---|---|---|
| 1 | Sept 2 | Introductions and Course Overview |
| 2 | Sept 8 | From Text to Matrices: Representing Text as Data |
| 3 | Sept 15 | Text Similarity, Text Re-use, and Complexity |
| 4 | Sept 22 | Supervised Learning I: Dictionary Methods and Out-of-Box Classifiers |
| 5 | Sept 29 | Supervised Learning II: Training Your Own Classifiers |
| 6 | Oct 6 | Unsupervised Learning: Topic Models |
| 7 | Oct 20 | Using Text to Measure Ideology – Scaling |
| 8 | Oct 27 | Representation Learning & Introduction to Deep Learning |
| 9 | Nov 3 | Word Embeddings: What They Are and How to Estimate |
| 10 | Nov 10 | Word Embeddings: Social Science Applications |
| 11 | Nov 17 | Replication Class: Students’ Presentation |
| 12 | Nov 24 | Transformers |
| 13 | Dec 1 | Large Language Models: Prompting, Chatbots, and Applications (Guest: Dr. Christopher Barrie, NYU) |
| 14 | Dec 8 | Final Projects: Students’ Presentation |
Between Replication and Transformers… I might have some updates…

Class Requirements
Math: Basic knowledge of calculus, probability, densities, distributions, statistical tests, hypothesis testing, the linear model, maximum likelihood and generalized linear models will help you in class.
Programming: Functional knowledge of R - main programming language of the course. Some Python at the end.
R is excellent for text analysis, and for some social science applications, better than Python
Free, and massive online community writing packages and extending modeling capabilities.
We will divide our learning between using
tidytextandquantedafor text analysis.Download RStudio IDE!
Python: we will do some, but later in the course!
How to do well in the class?
I designed this course as PhD style seminar:
On your pragrams, you learn a lot of DS/Stats techniques
You haven’t dig deep enough in a particular field. That’s what electives are for!
Heavy on readings - Lot’s of applied and technical readings.
Do the readings before class
Substantive readings are especially important, because they’ll help you understand what an interesting question looks like – in social science/public policy.
Plan ahead – particularly for the replication exercise
If you have a dataset you want work with, please bring it to class!
What our classes will look like.
This is a one meeting per week class. You should expect:
Between 1h-1.5h of lecture based on this week topics + readings
Your participation in the lecture is expected I will ask your insights about the readings.
Break (10min)
Coding.
- Mix of you working through some code I prepared.
- And I live-coding for you.
Logistics
Communication: via slack. Join the channel!
All materials: hosted on the class website: https://tiagoventura.github.io/PPOL_6801/
Syllabus: also on the website.
My Office Hours: Every Tuesday from 3 to 4pm. Just stop by!
Canvas: Only for communication! Materials will be hosted in the website!
Evalutation
| Assignment | Percentage of Grade |
|---|---|
| Participation/Attendance | 10% |
| Problem Sets | 30% |
| Replication Exercises | 20% |
| Final Project | 40% |
Participation
Active involvement during class sessions, fostering a dynamic learning environment.
Contributions made to your group’s ultimate project.
Assisting classmates with slack questions, sharing interesting materials on slack, asking question, and anything that provides healthy contributions to the course.
Problem Sets
| Assignment | Date Assigned | Date Due |
|---|---|---|
| No. 1 | Week 4 | Before EOD of Week 5’s class |
| No. 2 | Week 7 | Before EOD of Week 8’s class |
| No. 3 | Week 10 | Before EOD of Week 11’s class |
You will have a week to complete your assignments
individual assignment
distributed through GitHub
Replication Exercise
Opportunity to learn how science is made!
Work in randomly assigned pairs I will post on Slack.
Step 1: finding a paper to replicate (from the syllabus)
By the end of the week 3, you should select an article from the syllabus to be replicated by your team.
Inform the class on slack
“first come, first served”
Step 2: Acquiring the Data
- if you fail to get the data, pick another article.
Step 3: Presentation (week 11)
Step 4: Replication Repository on Github
Final Project
| Requirement | Due | Length | Percentage |
|---|---|---|---|
| Project Proposal | EOD Friday Week 8 | 2 pages | 5% |
| Presentation | Week 14 | 10-15 minutes | 10% |
| Project Report | Wednesday Week 15 | 10 pages | 25% |
The final project is composed of three parts:
- a 2 page project proposal: (which should be discussed and approved by me)
- an in-class presentation,
- A 10-page project report.
GenAI
You are allowed to use GenAI as you would use google in this class. This means:
Do not copy the responses from chatgpt – a lot of them are wrong or will just not run on your computer
Use chatgpt as a auxiliary source.
If your entire homework comes straight from chatgpt, I will consider it plagiarism.
If you use any GenAi Model, I ask you to mention on your code how it worked for you.
Questions?
R 101
Text-as-Data
Social Media