PPOL 6801 - Text as Data - Computational Linguistics
Week 5: Supervised Learning:
Training your own classifiers
Housekeeping
Today is your deadline for the problem set 1. Questions?
Coding
Replication
Replications next week
- Presentation (20 min each):
- Introduction;
- Methods;
- Results;
- Differences;
- Autopsy of the replication;
- Extensions
- Repository (by friday):
- Github Repo
- readme
- your presentation pdf
- code
- 5pgs report
- Github Repo
- Presentation (20 min each):
Where are we?
We started from pre-processing text as data, representing text as numbers, and describing features of the text.
Last week, we started measurement and classification:
- Dictionary Methods
- Discuss some well-known dictionaries
- Off-the-Shelf Classifiers
- Perspective API
- Hugging Face (only see as a off-the-shelf machines, LMMs later in this course)
- Today: Supervised Learning
From dictionaries to supervised learning
How can we systematically classify text into meaningful categories (e.g., positive/negative, hate vs. non-hate speech, spam vs. non-spam)?
Goal: Learn a function f that maps text inputs x to category outputs y
Dictionaries: Mapping function is explicitly defined by the researcher using predefined word lists
Supervised Classification: Mapping function is learned from the data by training an algorithm to predict categories based on labeled documents
What is Supervised Learning?
Def: machine learning algorithm type that requires labeled input data to understand the mapping function from the input to the output
SUPERVISED: The true labels y act as a “supervisor” for the learning process
- Model predicts ˆy for each input x
- Compare predictions ˆy to true labels y
- Adjust model to minimize errors
LEARNING: the process by which a machine/model improves its performance on a specific task
Quick introduction to Machine Learning
An Statistical Model
The aim of statistical models is to estimate the relationship between the outcome and some set of variables:
\[ y = f(X) + \epsilon\]
Where:
\(y\) is the outcome/dependent/response variable
\(X\) is a matrix of predictors/features/independent variables
\(f()\) is some fixed but unknown function mapping X to y. The “signal” in the data
\(\epsilon\) is some random error term. The “noise” in the data.
Supervised Learning in TaD
Consider this task: “Predicting sentiment of news about the economy in the US”.
Inference or Prediction?
| Component | Definition | Example in This Case |
|---|---|---|
| Input Features (x) | ||
| Label (y) | ||
| Prediction (ŷ) |
| Component | Definition | Example in This Case |
|---|---|---|
| Input Features (x) | Textual data (e.g. DFM) | Sentiment scores from news |
| Label (y) | True category or outcome we want to predict | hand-coded sentiment on a small set of news |
| Prediction (ŷ) | Model’s estimated prediction | Predicted sentiment |
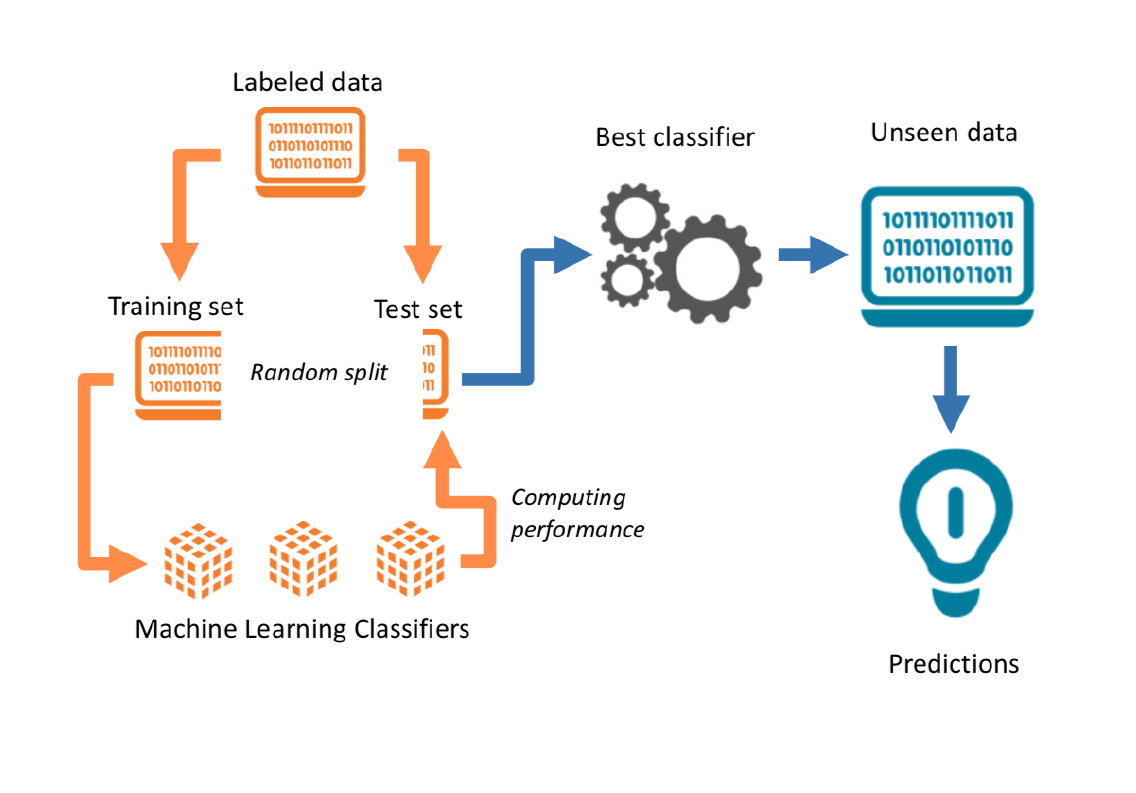
Supervised Learning Pipeline
Step 1: Label some examples of the concept of we want to measure
Step 2: Train a statistical model on these set of label data using the document-feature matrix as input on a training dataset.
Step 3: Choose a model (transformation function) that gives higher out-of-sample accuracy
Step 4: use the classifier - some f(x) - to predict unseen documents.
Start with your target: Building a training dataset.
How to obtain a training labeled dataset?
External Source of Annotation: Someone else labelled the data for you
- Federalist papers
- Metadata from text
- Manifestos from Parties with well-developed dictionaries
Expert annotation:
- mostly undergrads ~ that you train to be experts
Crowd-sourced coding: digital labor markets
- Wisdom of Crowds: the idea that large groups of non-expert people are collectively smarter than individual experts when it comes to problem-solving
Crowdsourcing as a research tool for ML
Crowdsourcing is now understood to mean using the Internet to distribute a large package of small tasks to a large number of anonymous workers, located around the world and offered small financial rewards per task. The method is widely used for data-processing tasks such as image classification, video annotation, data entry, optical character recognition, translation, recommendation, and proofreading
Source: Benoit et al, 2016
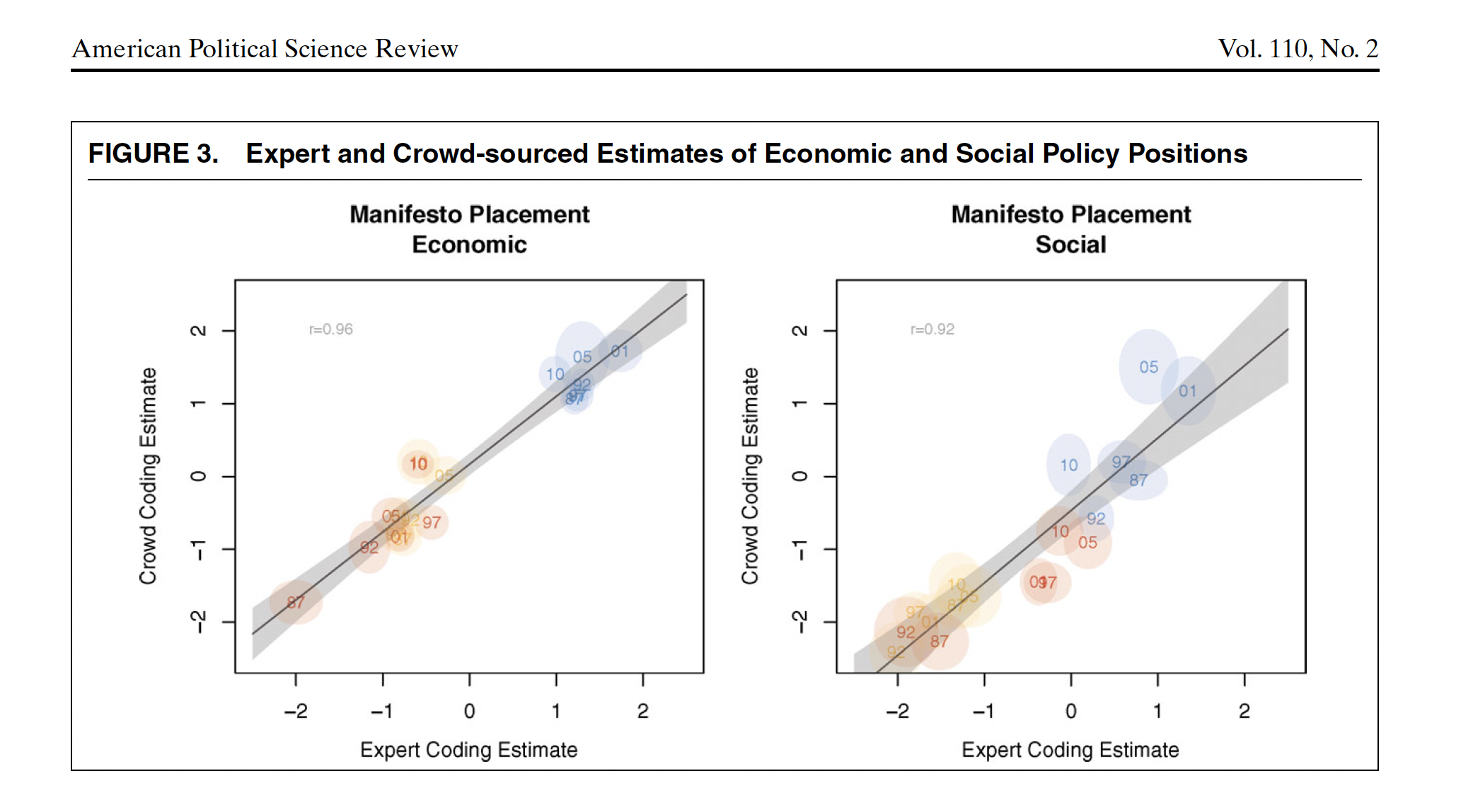
Benoit et al, 206: Crowdsourcing Political Texts
Expert annotation is expensive.
Benoit, Conway, Lauderdale, Laver and Mikhaylov (2016) note that classification jobs could be given to a large number of relatively cheap online workers
Multiple workers ~ similar task ~ same stimuli ~ wisdom of crowds!
Representativeness of a broader population doesn’t matter ~ not a populational quantity, it is just a measurement task
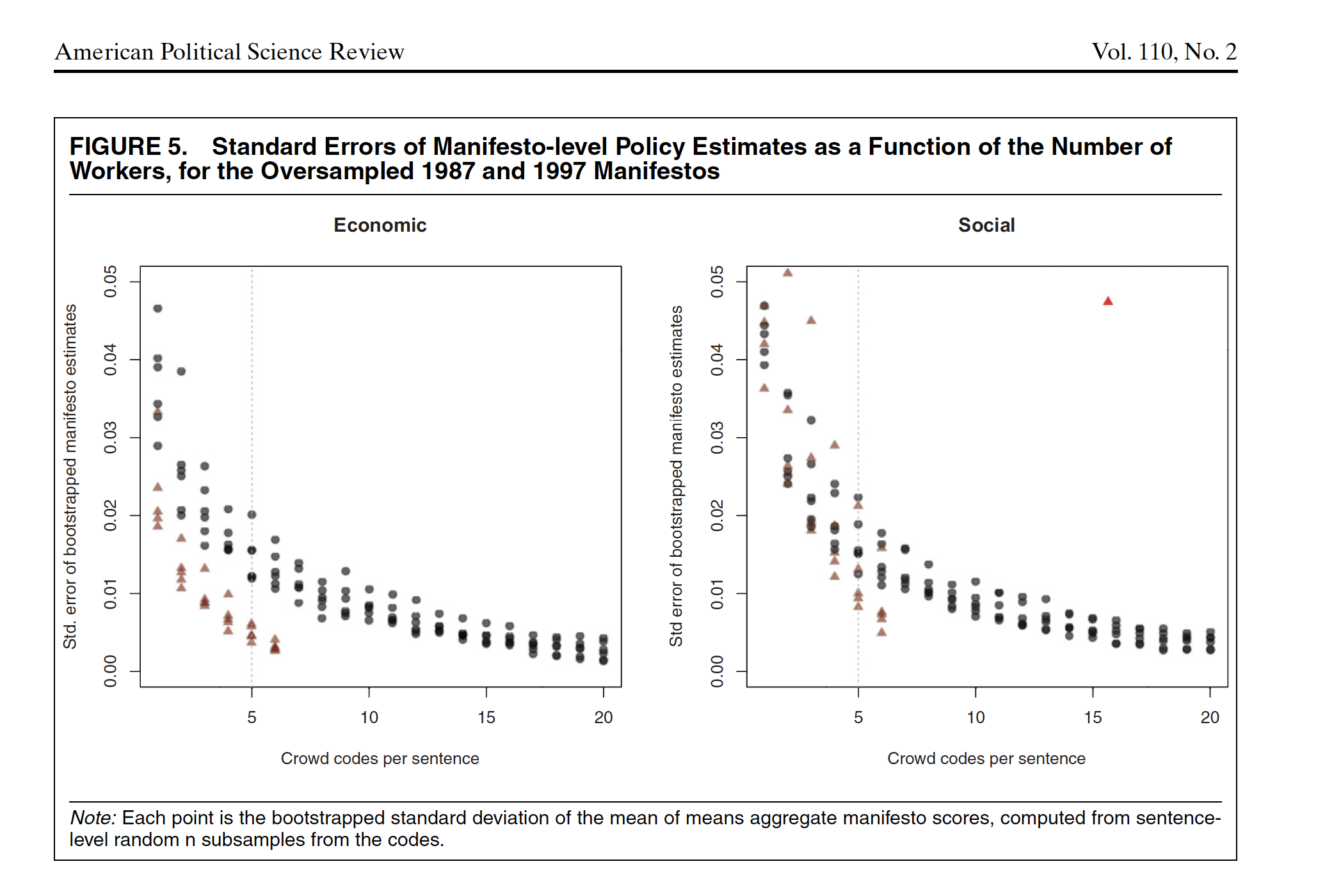
Their task: Manifestos ~ sentences ~ workers:
- social|economic
- very-left vs very right
- social|economic
Reduce uncertainty by having more workers for each sentence
Comparing Experts and online workers
How many workers?
Example of Crowdsourcing for labels
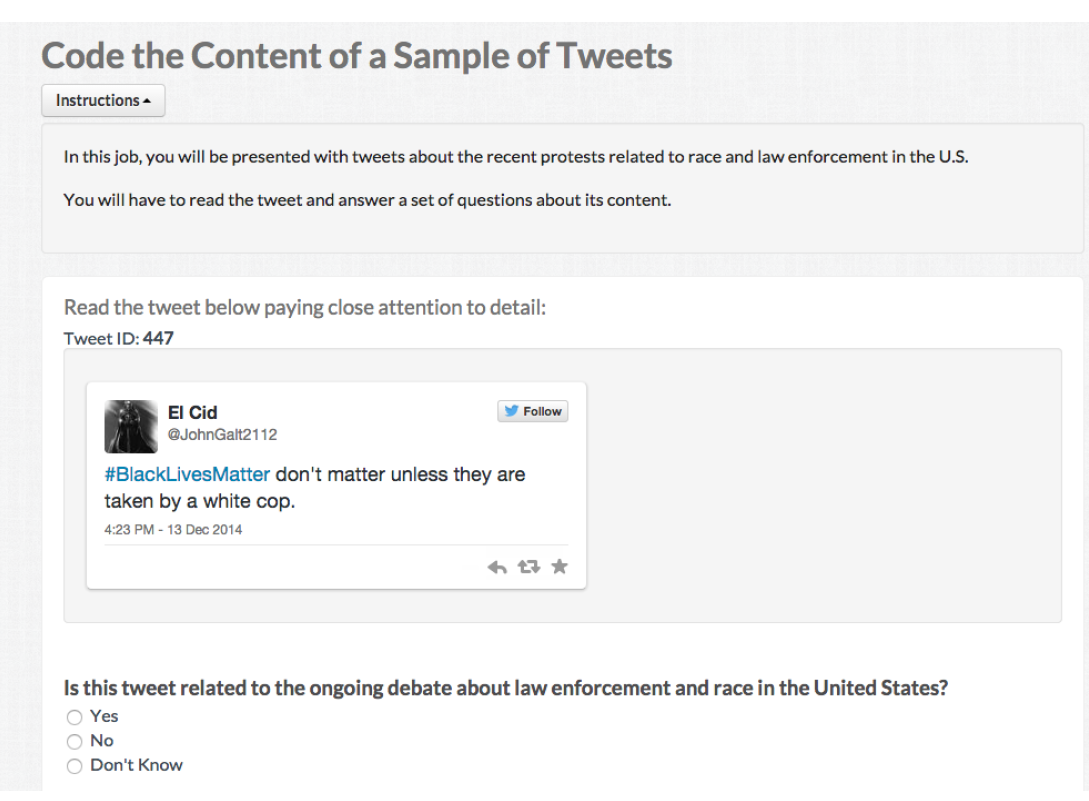
Source: Pablo Barbera’s CSS Seminar
Training an statistical model.
Classifier Selection
- Def: A classifier is an statistical model that assigns data points to a range of categories or classes.
in text as data, often your DFM has Features > Documents
- identification problems for statistical models
- overfitting the data with noise
Bias-Variance Trade-off
- fit a overly complicated model ~ leads to higher variance
- fit a more flexible model ~ leads to more bias
Many models:
- Naive Bayes, Regularized regressionm, SVM, k-nearest neighbors, tree-based methods, Ensemble methods + DL
- Differences: loss function they minimize, model assumptions, regularization control (balance bias vs. variance), computational complexity
Regularized OLS Regression
The simplest, but highly effective, way to build ML models in TaD is to use known model (OLS) + regularization to reduce dimensionality:
OLS Loss Function :
\[ RSS = \sum_{i=1}^{N} \left( y_i - \beta_0 - \sum_{j=1}^{J} \beta_j x_{ij} \right)^2 \]
OLS + Penalty (Ridge)
\[ \text{RSS} = \sum_{i=1}^{N} \left( y_i - \beta_0 - \sum_{j=1}^{J} \beta_j x_{ij} \right)^2 + \lambda \sum_{j=1}^{J} \beta_j^2 \rightarrow \text{ridge regression} \]
Penalizes large coefficients.
Shrinks all coefficients towards zero, but none are exactly zero.
OLS + Penalty (Lasso)
\[ \text{RSS} = \sum_{i=1}^{N} \left( y_i - \beta_0 - \sum_{j=1}^{J} \beta_j x_{ij} \right)^2 + \lambda \sum_{j=1}^{J} |\beta_j| \rightarrow \text{lasso regression} \]
Penalizes absolute size of coefficients.
Many coefficients shrink to exactly zero → automatic variable selection.
VERY USEFUL FOR SPARSE MATRIX!!
Many Models
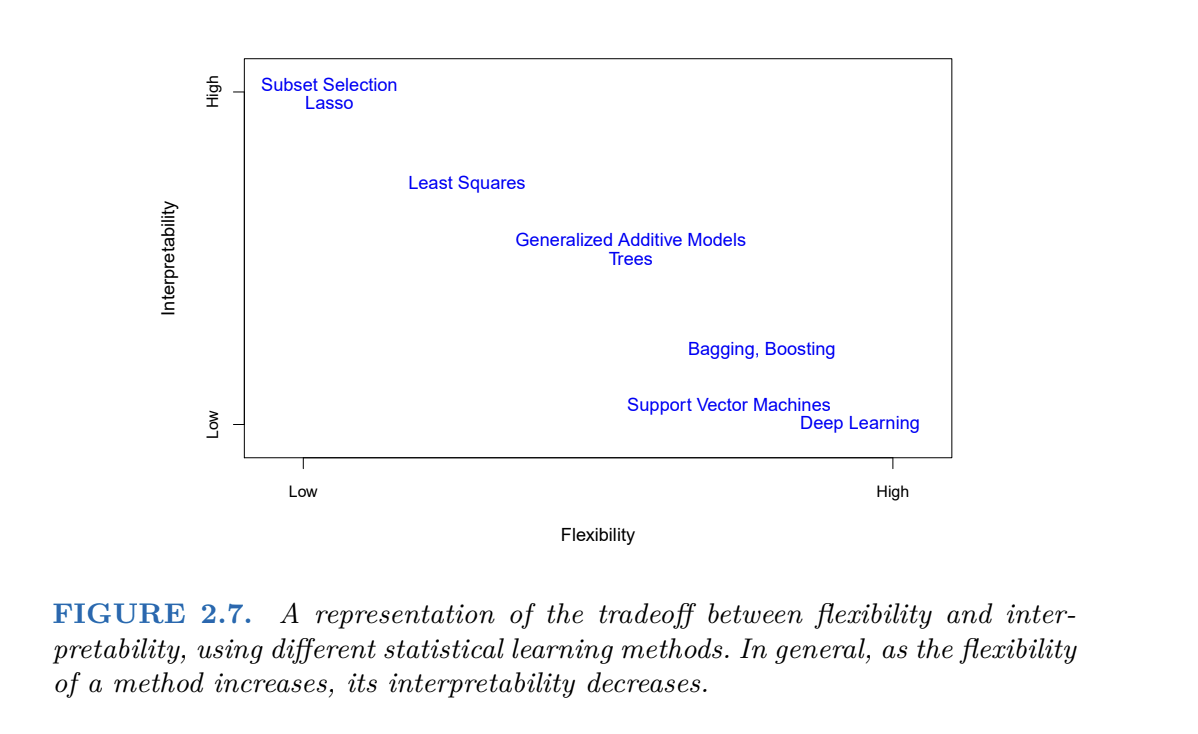
- Differences: loss function they minimize, model assumptions, regularization control (balance bias vs. variance), computational complexity
How to select a model?
The purpose of training the model is to capture signal and ignore noise.
To do so:
Define a accuracy metric: reduce this metric as much as possible. Simplest form: how many errors I am making with the predictions?
Train-Test Split
Split your data between training and test
Training data: find the best model and tune the parameters of these models
Test data: assess the accuracy of your model.
Select the model based on smaller out of sample predictive accuracy, using UNSEEN data.
What can go wrong?
Bias and Variance Trade-off
Expected prediction error for a data point:
\[ E\big[(\hat{y} - y)^2\big] = (\text{Bias}^2) + \text{Variance} + \text{Irreducible Error} \]
Bias: Difference between the expected prediction of the model and the true value.
\[\text{Bias}(\hat{f}(x)) = E[\hat{f}(x)] - f(x)\]
Variance: How much do the model’s predictions fluctuate for different training sets?
\[ \text{Var}(\hat{f}(x)) = E\Big[\big(\hat{f}(x) - E[\hat{f}(x)]\big)^2\Big]\]
Bias and Variance Tradeoff:
Can fit a very complicated model to our training set perfectly
- Bias ↓, Variance ↑
Can be more relaxed about the performance in the training set
- Bias ↑, Variance ↓
Bias and Variance Tradeoff

Train-Validation-Test
Training Set
- Largest portion (60-80% of the data)
- To train the model
Validation Set
- Smaller portion (10-20% of data)
- Check different models
- To tune hyperparameters and evaluate model during training
- Parameters that we set before training begins (e.g. learning rate, number of neural networks layers, strength of regularization)
Test Set - Smaller portion (10-20% of data) - To assess final model performance
Or Cross Validation
Cross-validation: resampling method that involves partitioning data into subsets, allowing us to train and test on different combinations
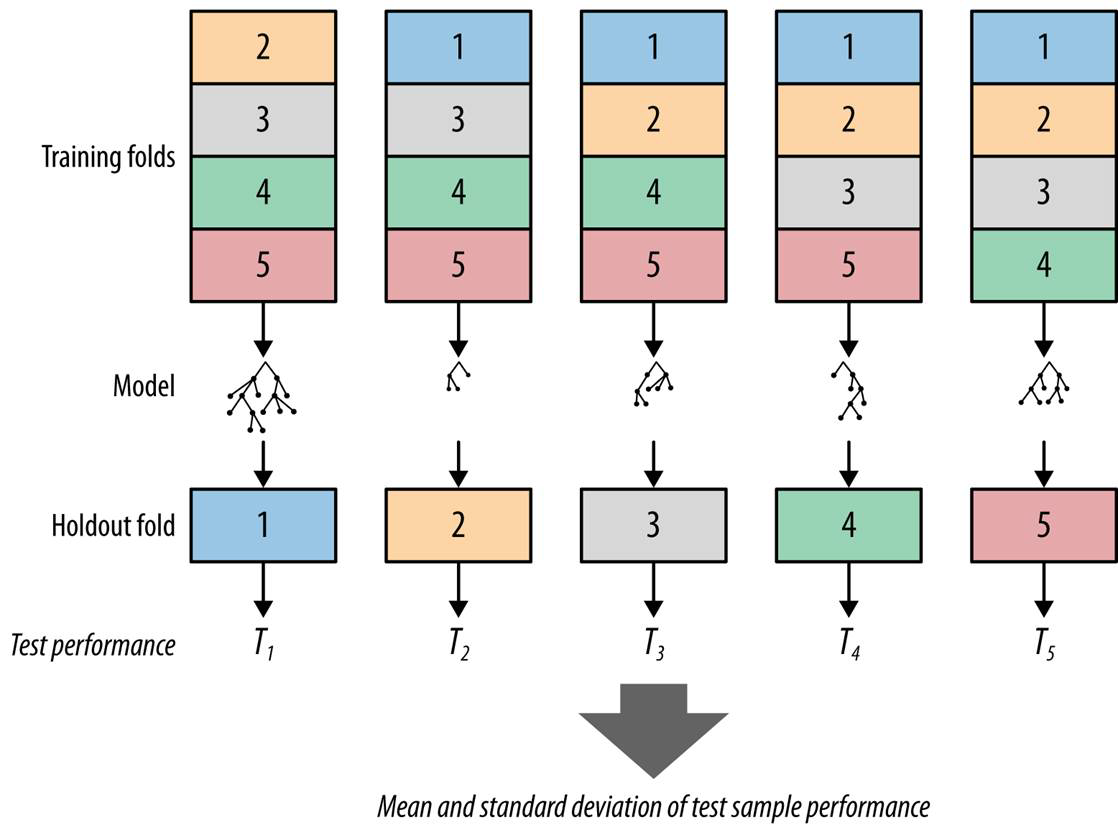
Summary: how to choose a classifier?
| Factor | Recommended Classifiers |
|---|---|
| Task Type | Classification: Logistic Regression, Random Forest, SVM Regression: Linear Regression, Random Forest Regressor |
| Data Size | Small datasets: Logistic Regression, Naive Bayes Large datasets: Neural Networks, Gradient Boosting |
| Feature Characteristics | Sparse features (e.g., text data): Naive Bayes, SVM Non-linear relationships: Random Forest, Gradient Boosting |
| Interpretability | High interpretability: Logistic Regression, Decision Trees Performance focus: Neural Networks, Gradient Boosting |
| Computational Resources | Low resources: Naive Bayes, Logistic Regression High resources: Neural Networks, Gradient Boosting |
Measures of Accuracy
Evaluating the Performance
| Predicted | ||||
|---|---|---|---|---|
| J | ¬J | Total | ||
| Actual | J | a (True Positive) | b (False Negative) | a+b |
| ¬J | c (False Positive) | d (True Negative) | c+d | |
| Total | a+c | b+d | N |
Accuracy: number correctly classified/total number of cases = (a+d)/(a+b+c+d)
Precision : number of TP / (number of TP+number of FP) = a/(a+c) .
- Fraction of the documents predicted to be J, that were in fact J.
- Think as a measure for the estimator (Very precise estimate)
Recall: (number of TP) / (number of TP + number of FN) = a /(a+b)
- Fraction of the documents that were in fact J, that method predicted were J.
- Think as a measure for the data (Covers most of the cases in the data)
F : 2 precision*recall / precision+recall
- Harmonic mean of precision and recall.
Quizz
You are working for the FBI, looking for emails that pertain to terrorist attacks. Fortunately, such emails are very, very rare (0.0001% of all emails).
For such tasks, there’s a trade-off between precision and recall. Explain why.
We may be skeptical of using accuracy as a performance indicator in this case. Explain why.
If the FBI uses a very strict filter (only flags emails that look very suspicious), precision will be high (almost everything flagged is truly relevant) but recall will be low (many relevant emails missed).
If the FBI uses a lenient filter (flags lots of emails), recall will be high (most relevant ones are caught), but precision will drop (many false alarms).
Because terrorist emails are extremely rare, improving one metric usually comes at the expense of the other.
Missing a terrorist email (false negative) is much worse than flagging many innocent ones (false positives).
Thus, the solution is to prioritize recall (don’t miss positives), even if precision is lower — then use human analysts to review flagged cases
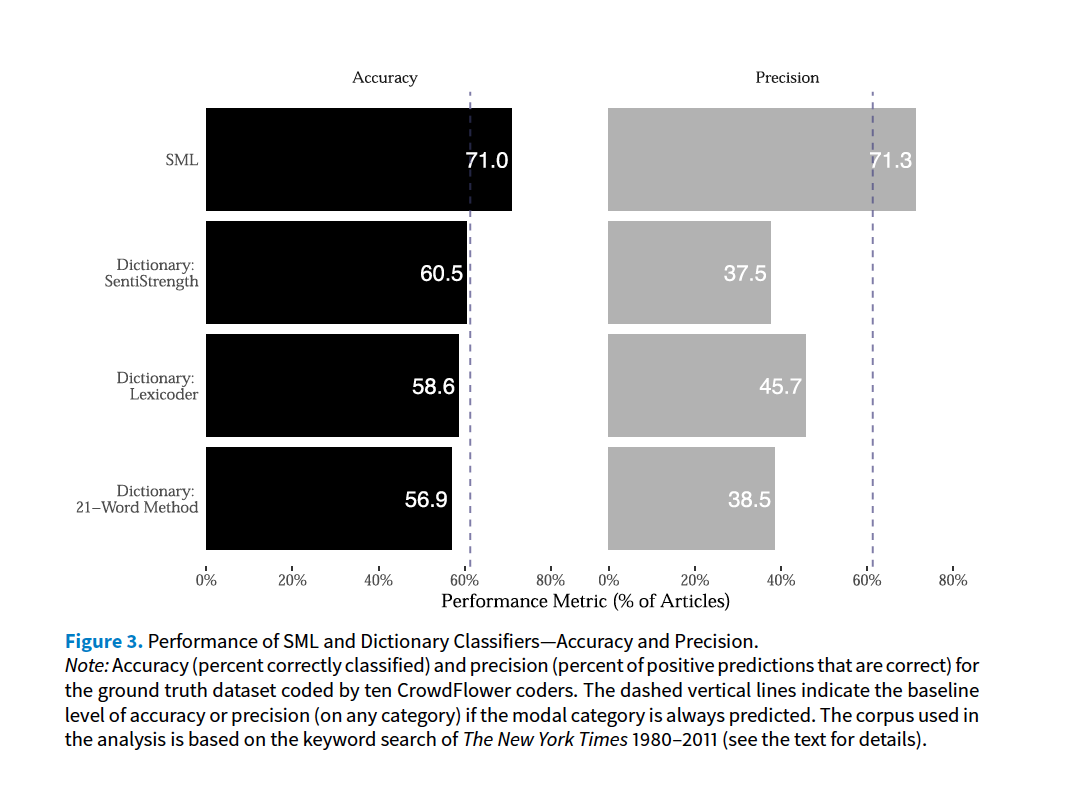
Barbera et al, 2020, Guide for Supervised Models with Text
Task: Tone of New York Times coverage of the economy. Discusses:
- How to build a corpus
- Unit of analysis
- Unique documents or More coders?
- ML or Dictionaries?
How to build a corpus?

Unit of Analysis?

Unique documents or More coders?

ML or Dictionaries?