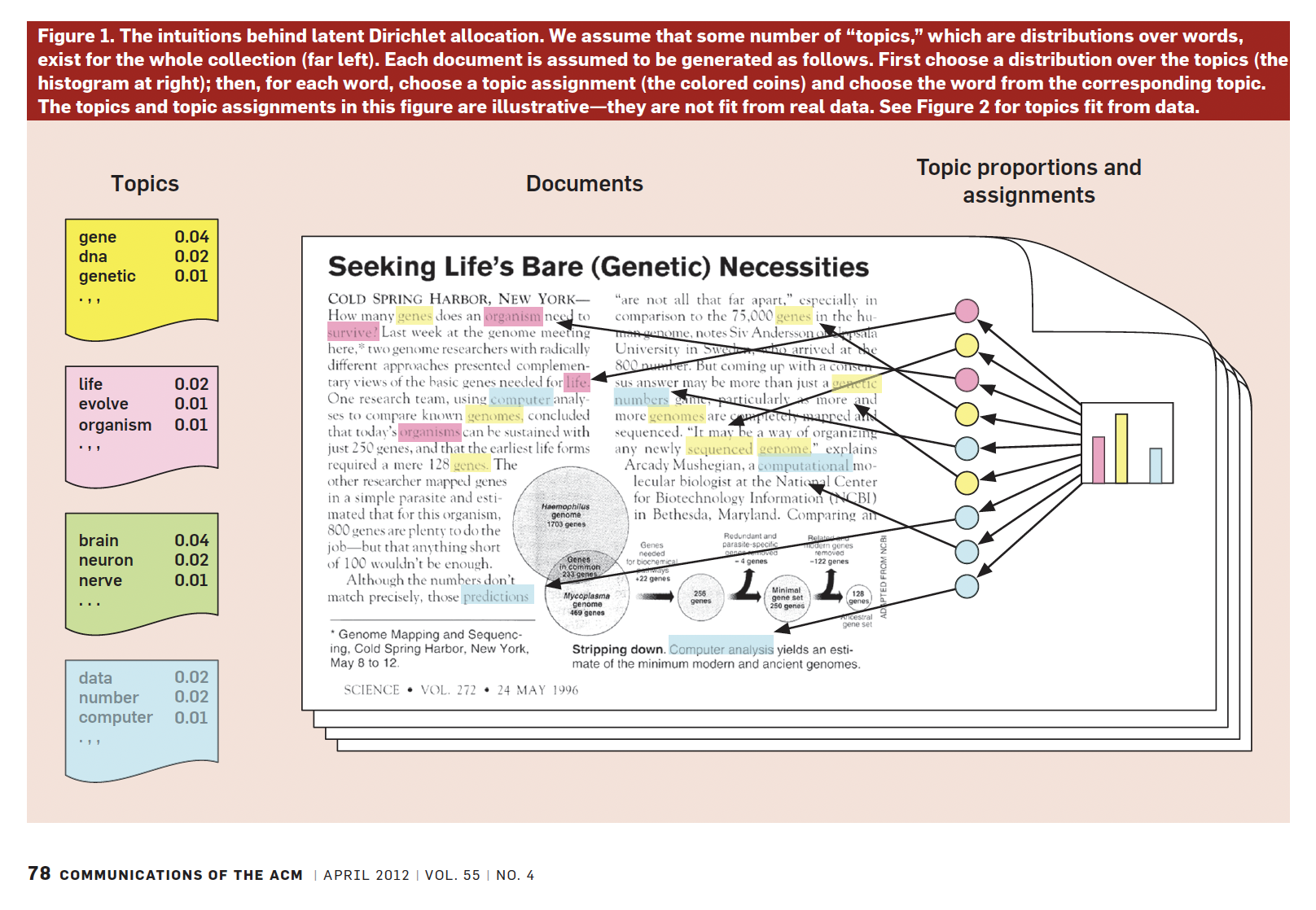
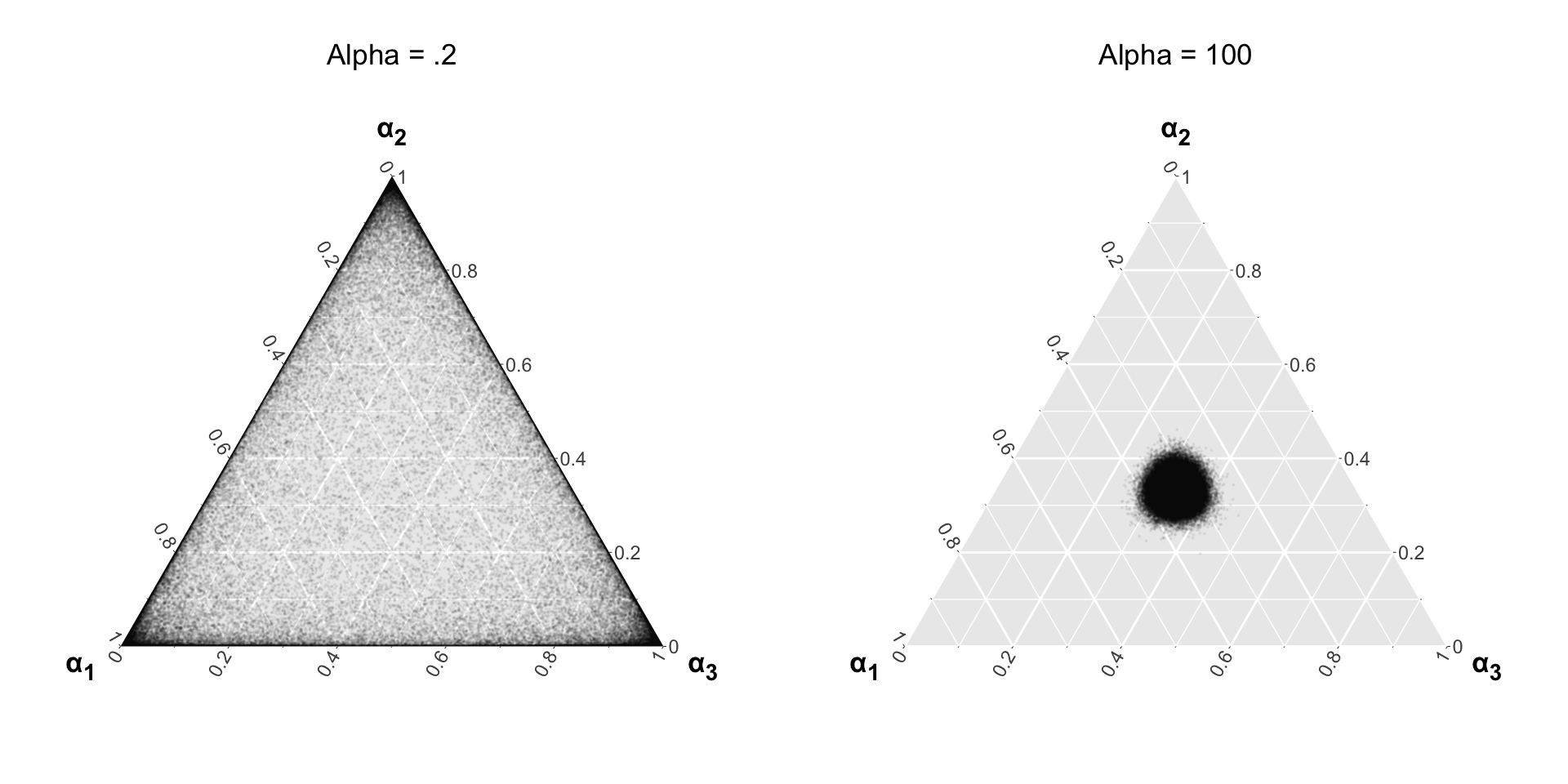
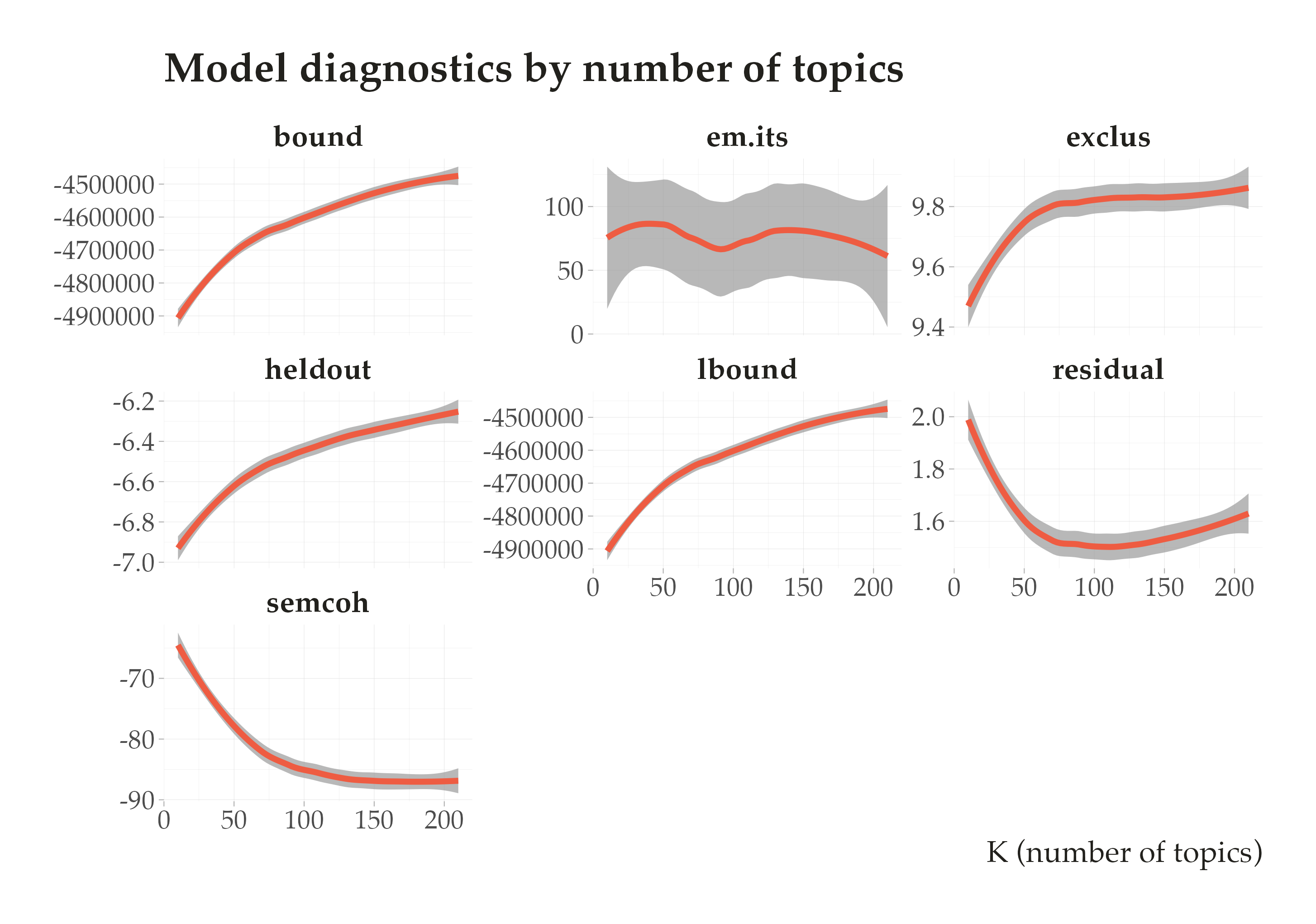
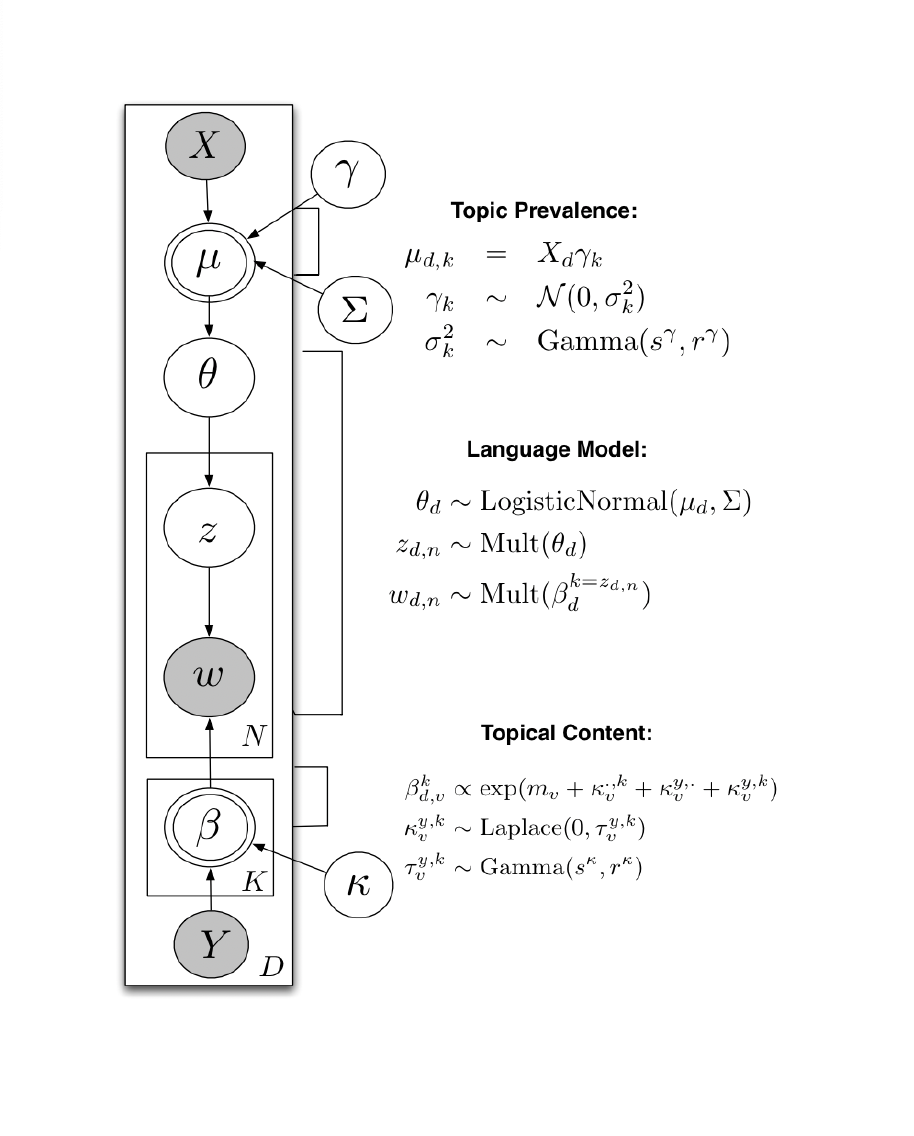
Inference: How to estimate all these parameters?
Inference: Use the observed data, the words, to make an inference about the latent parameters: the \(\beta\)s, and the \(\theta\)s.
We start with the joint distribution implied by our language model (Blei, 2012):
\[
p(\beta_{1:K}, \theta_{1:D}, z_{1:D}, w_{1:D})= \prod_{K}^{i=1}p(\beta_i)\prod_{D}^{d=1}p(\theta_d)(\prod_{N}^{n=1}p(z_{d,n}|\theta_d)p(w_{d,n}|\beta_{1:K},z_{d,n})
\]
To get to the conditional:
\[
p(\beta_{1:K}, \theta_{1:D}, z_{1:D}|w_{1:D})=\frac{p(\beta_{1:K}, \theta_{1:D}, z_{1:D}, w_{1:D})}{p(w_{1:D})}
\]
The denominator is hard to be estimated (requires integration for every word for every topic):
- Simulate with Gibbs Sampling or Variational Inference (Bayesian stats)