PPOL 6801 - Text as Data - Computational Linguistics
Week 10: Word Embeddings II
Professor: Tiago Ventura
Plans for Today:
Quick introduction to Word Embedding + Matrix Factorization
Coding
In class Exercise: Applied Readings
Estimating Word Embeddings
Approches:
- Neural Networks: rely on the idea of self-supervision
- use unlabeled data and use words to predict sequence
- the famous word2vec algorithm
- Skipgram: predicts context words
- Continuous Bag of Words: predict center word
- Count-based methods: look at how often words co-occur with neighbors.
- Use this matrix, and use some factorization to retrieve vectors for the words
- Fast, not computationally intensive, but not the best representation, because it is not fully local
- This approach is somewhat implemented by the “GloVE” algorithm
Neural Networks Approach
We saw ONE way to estimate word vectors with neural networks: Word2Vec
However, at this point in time, we actually do not really use Word2Vec embedding in modern DL
Consider Word2Vec as a general approach of learn dense representation of words via self-supervision.
But… you will have many many many distinct NN architectures doing this.
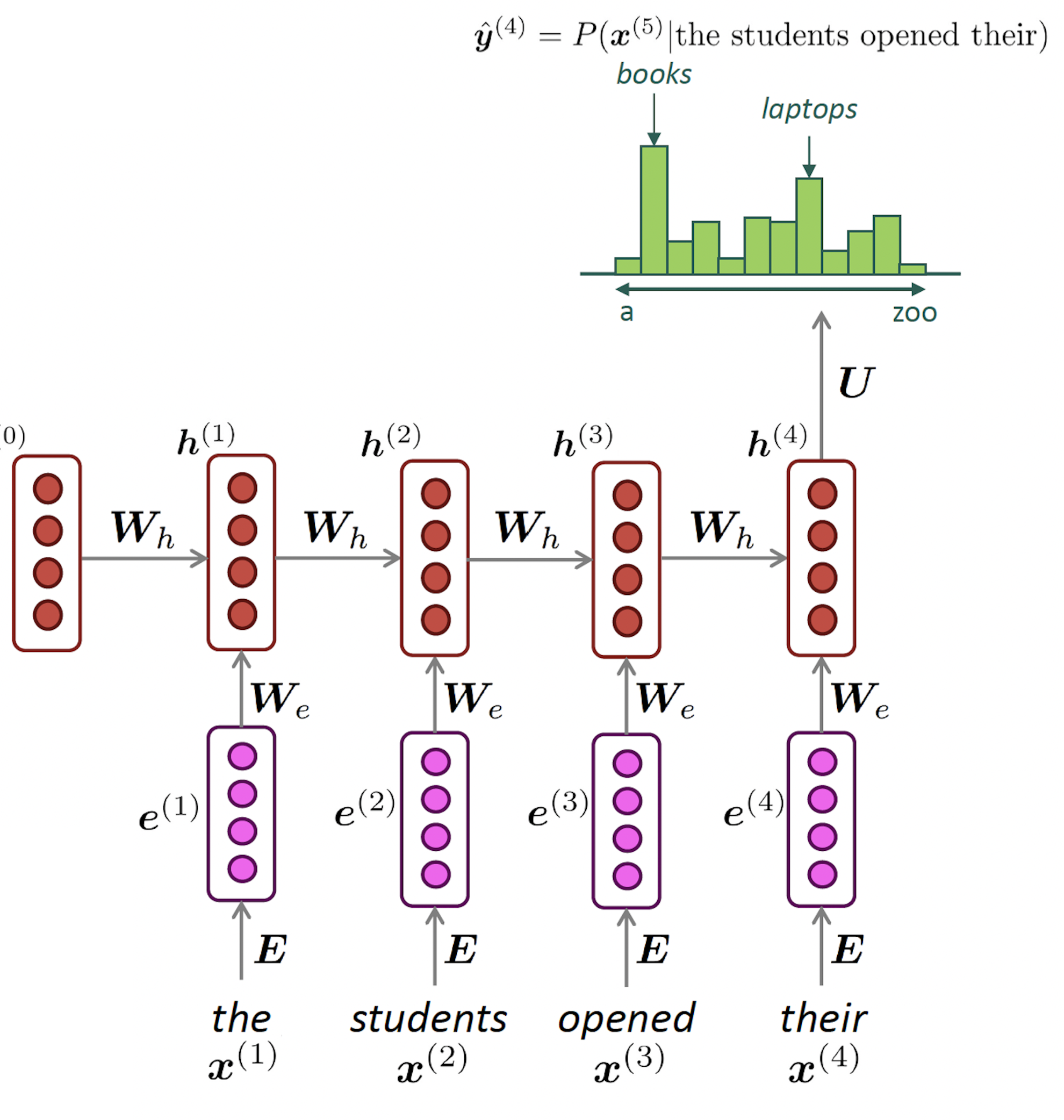
Recurrent Neural Networks
Transformers
![]()
Word Embeddings via Count Based Methods (No Deep Learning)
Count Based Approaches
Count-based methods rely on word co-occurrence to learn embeddings:
Compute Unigram Probabilities: Measure how often each word appears in the corpus
Compute Word Co-occurrences: Count how often words appear together across the entire corpus
Calculate PMI (Pointwise Mutual Information): Measures how much more often two words co-occur than expected by chance
\[ PMI(\text{word}_1, \text{word}_2) = \log \frac{P(\text{word}_1, \text{word}_2)}{P(\text{word}_1) \, P(\text{word}_2)} \]
Construct a Co-occurrence Matrix: Store PMI values in a large word-by-word matrix
Apply Singular Value Decomposition (SVD): Reduce the matrix to extract meaningful lower-dimensional word vectors
SVD is a matrix factorization technique used in linear algebra and data science
Reduces dimensionality by identifying important patterns in data: splits the matrix into fundamental patterns (singular vectors), ranked by importance (singular values)
- Love this youtube video here: https://www.youtube.com/watch?v=vSczTbgc8Rc
Glove algorithm is a variation of this approach.
Coding!
Applications
Let’s discuss now several applications of embeddings on social science papers. These paper show:
How to use embeddings to track semantic changes over time
How to use embeddings to measure emotion in political language.
How to use embeddings to measure gender and ethnic stereotypes
And a favorite of political scientists, how to use embeddings to measure ideology.
In class exercise
Work in pairs
Each pair will select one of the five applied papers for this week
Prepare a presentation about this paper for your colleagues (30min)
Your presentation needs to answer three key questions:
How are word embeddings used?
What substantive/applied insights are extracted from the embeddings approach?
Could this be done with non-embeddings methods (any of the things we saw before embeddings)?
Every group will have 5 minutes to present
Papers and pairs
Rodman, E., 2020. A Timely Intervention: Tracking the Changing Meanings of Political Concepts with Word Vectors. Political Analysis, 28(1), pp.87-111.
Gennaro, Gloria, and Elliott Ash. “Emotion and reason in political language.” The Economic Journal 132, no. 643 (2022): 1037-1059.
Rheault, Ludovic, and Christopher Cochrane. “Word embeddings for the analysis of ideological placement in parliamentary corpora.” Political Analysis 28, no. 1 (2020): 112-133.
Austin C. Kozlowski, Austin C., Matt Taddy, and James A. Evans. 2019. “The Geometry of Culture: Analyzing the Meanings of Class through Word Embeddings.” American Sociological Review 84, no. 5: 905–49.
Garg, Nikhil, Londa Schiebinger, Dan Jurafsky and James Zou. 2018. “Word embeddings quantify 100 years of gender and ethnic stereotypes.” Proceedings of the National Academy of Sciences 115(16):E3635–E3644.