Terminology
Transformers: Neural architectures built around multihead self-attention
RNN: Non-transformers, Recurrent Neural Network, processes sequences sequentially, inputs static embeddings, outputs probability over vocabulary
LSTM: Non-Transformers, Long Short-Term Memory network, an enhanced RNN with gating mechanisms.
Bert: Encoder only Transformer, pretrained on unlabeled text to predict masked tokens in a sentence, ~ 300M parameters. Other similar models: RoBERTa, DiBERTa, XLMRoBERTa, among others
LLMs: Large Language Models. Language models (next word prediction) based on Transformer, often Decoder only models
GPT-x: A decoder-only autoregressive transformer, owned by OPENAI. GPT-3 has ~ 175 billion parameters
LLama: also decoder model, owned by META, trying to keep up with OpenAI
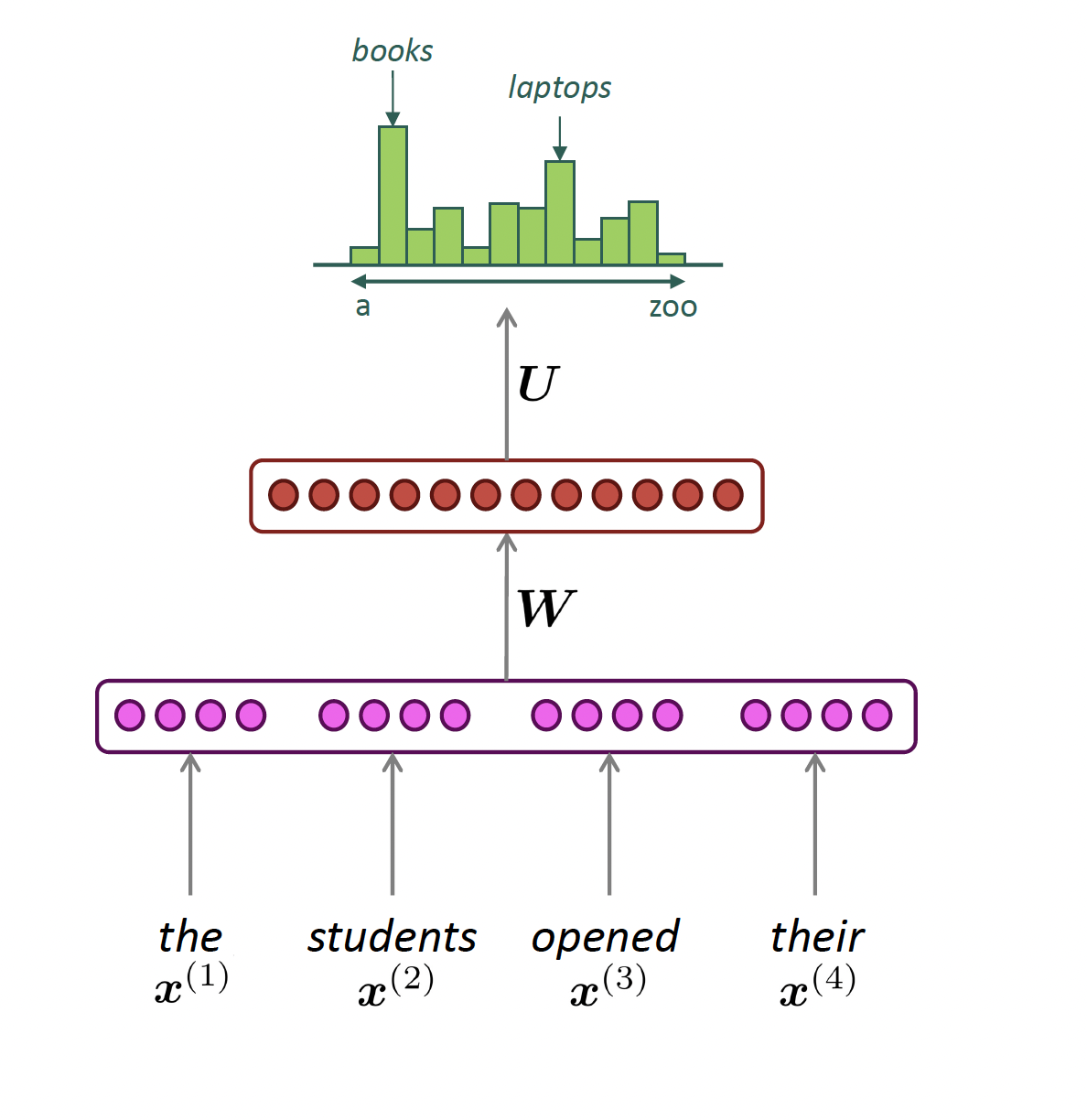
Fixed Window Neural Language Model
output distribution
\[\hat{y} = \mathrm{softmax}(U h + b_2) \in \mathbb{R}^{|V|}\]
hidden layer
\[h = f(W e + b_1)\]
concatenated word embeddings
\[e = [e^{(1)}; e^{(2)}; e^{(3)}; e^{(4)}]\]
words / one-hot vectors
\[x^{(1)}, x^{(2)}, x^{(3)}, x^{(4)}\]
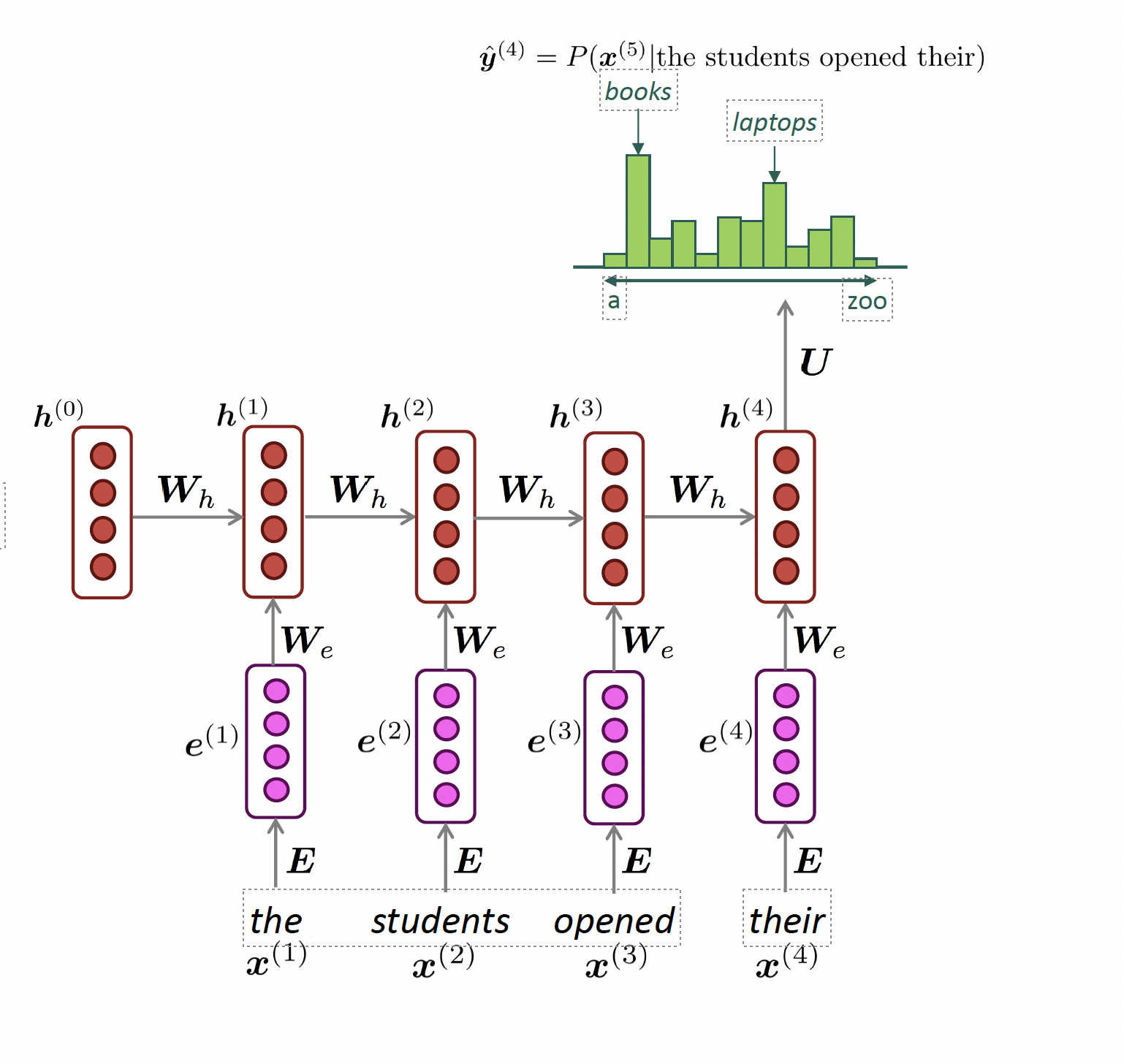
Reccurrant Neural Network (RNN)
Def: Neural network architecture that processes sentences sequentially with hidden states that carry over-time information.
output distribution
\[\hat{y}^{(t)} = \mathrm{softmax}\left(U h^{(t)} + b_2\right) \in \mathbb{R}^{|V|}\]
hidden states
\[h^{(t)} = \sigma\left(W_h h^{(t-1)} + W_e e^{(t)} + b_1\right)\]
\[h^{(0)} \text{ is the initial hidden state}\]
word embeddings
\[ e^{(t)} = E x^{(t)} \]
words / one-hot vectors
\[x^{(t)} \in \mathbb{R}^{|V|}\]
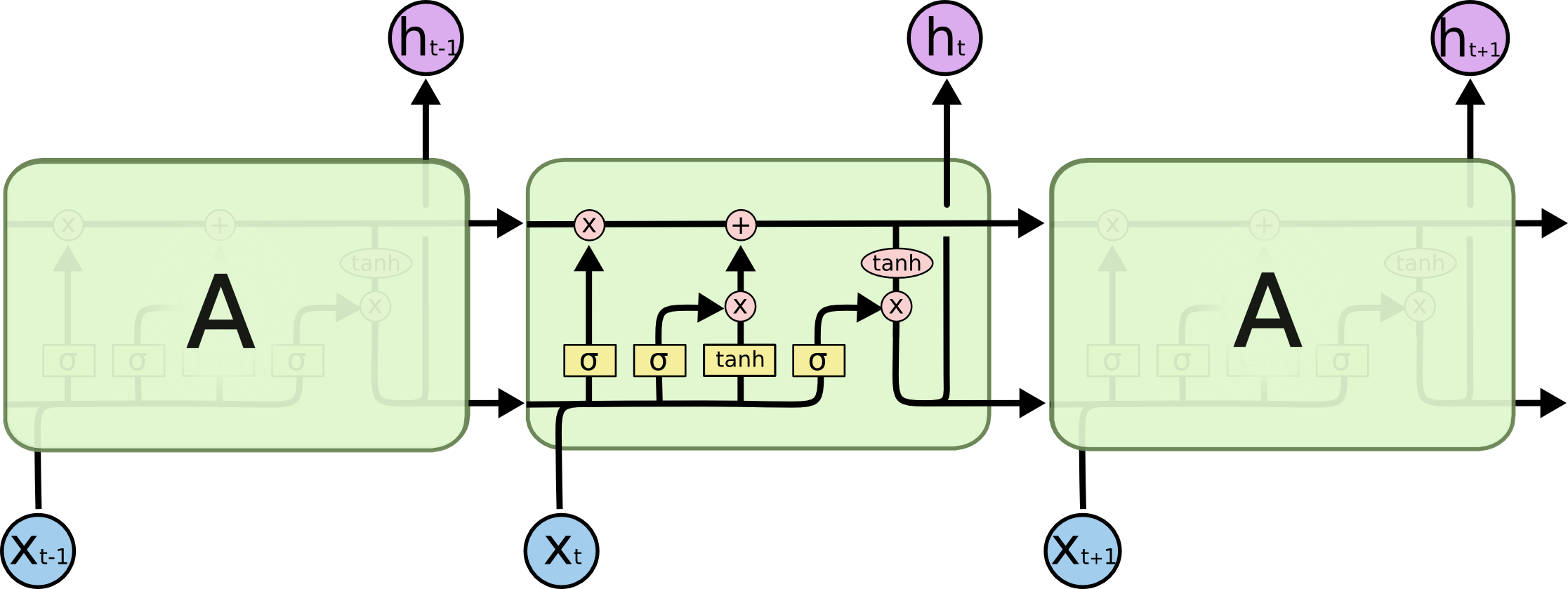
LSTM
Def: A RNN with gated cells. Each gated cell has several matrix multiplication + non-linearity variations, and allows each hidden state to store, update, and forget information from previous steps.
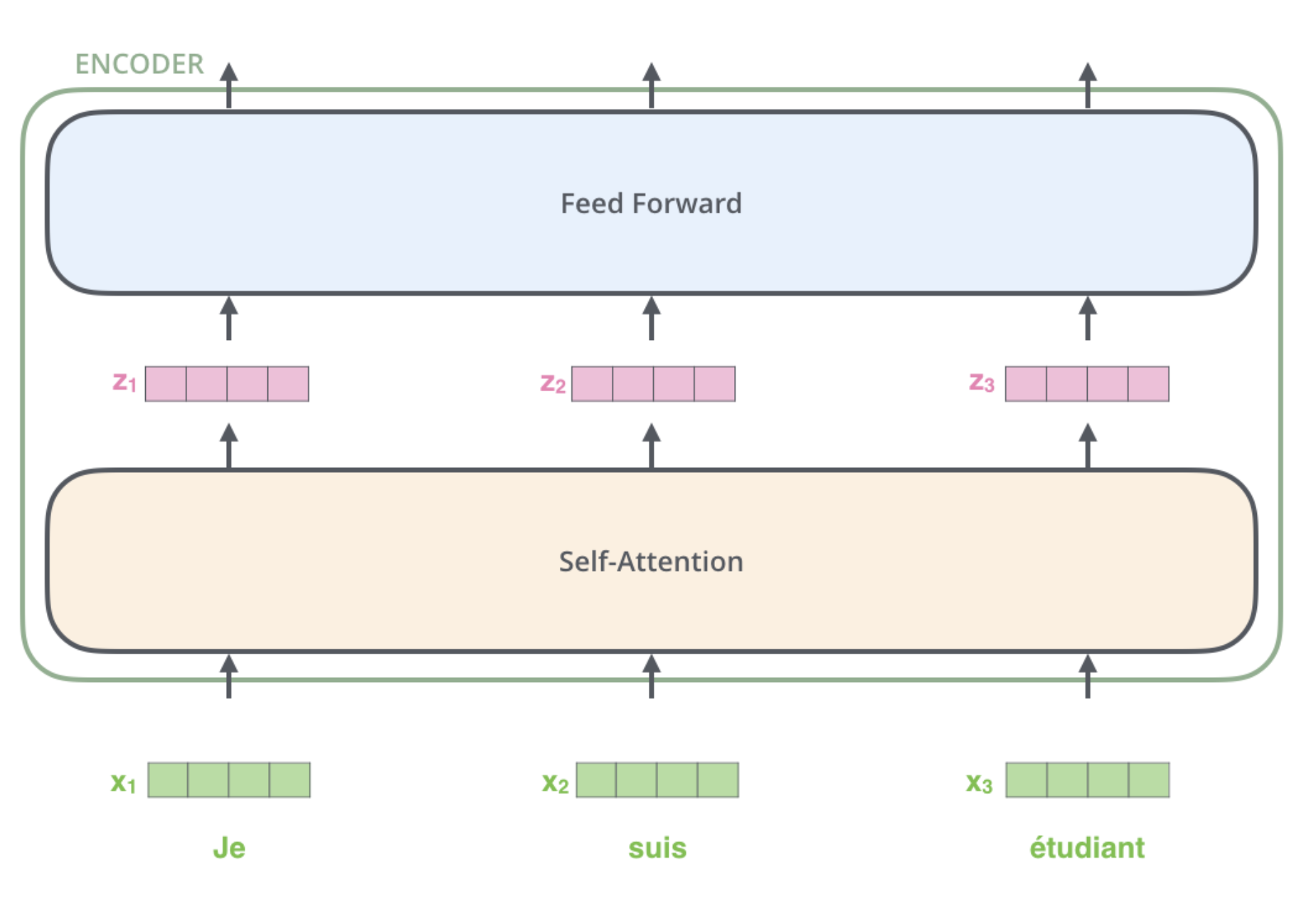
Feature 2: Self-Attention
Self-Attention: Definition
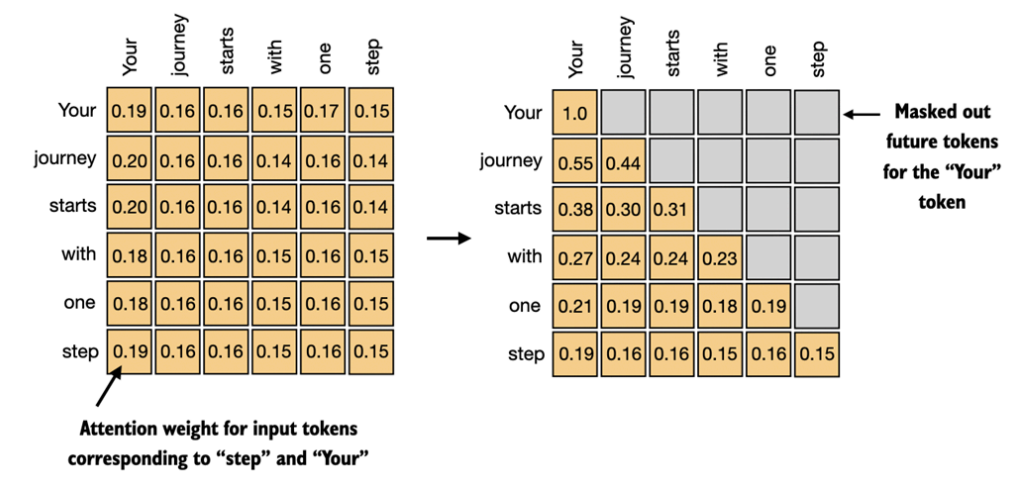
Def: the mechanism in the transformer that weighs and combines the representations of context words in the token encoding
Word2vec: the representation of a word’s meaning is always the same vector irrespective of the context
- the vector for ‘bear’ is the same, no matter if it refers to a ‘teddy bear’,a ’black bear”, or a the show “the bear”.
Transformers can build contextual representations of word meaning (contextual embeddings) by encoding the meaning of contextual words into the token representation.
The encoder will input a static embedding for each token, but output a contextual embedding for the token in the sentence
Self-Attention: Intuition
Consider these sentences:
“It” refers to different nouns in each sentence.
If we read the sentences from left to right, we get: The chicken didn’t cross the road because it…. ?
At this point, we don’t know what “it” is referring to.
One of the fundamental limitations of RNNs was that you must walk through the sequence one word at a time. Self-attention solves many of these issues!
Self-Attention Hypothetical example
Attention estimates each word’s representation via information from embeddings from contextual words.
![]()
Self-Attention: Simple Example
Assume \(\mathbf{w}_{1:n}\) be a sequence of words in vocabulary, as a one-hot encoding.
Step 1: For each word \(w_i\), let’s start with a static embedding using a look-up:
\[
x_i = E w_i,
\]
With E having the dimensions d (embedding size) and V (vocabulary size)
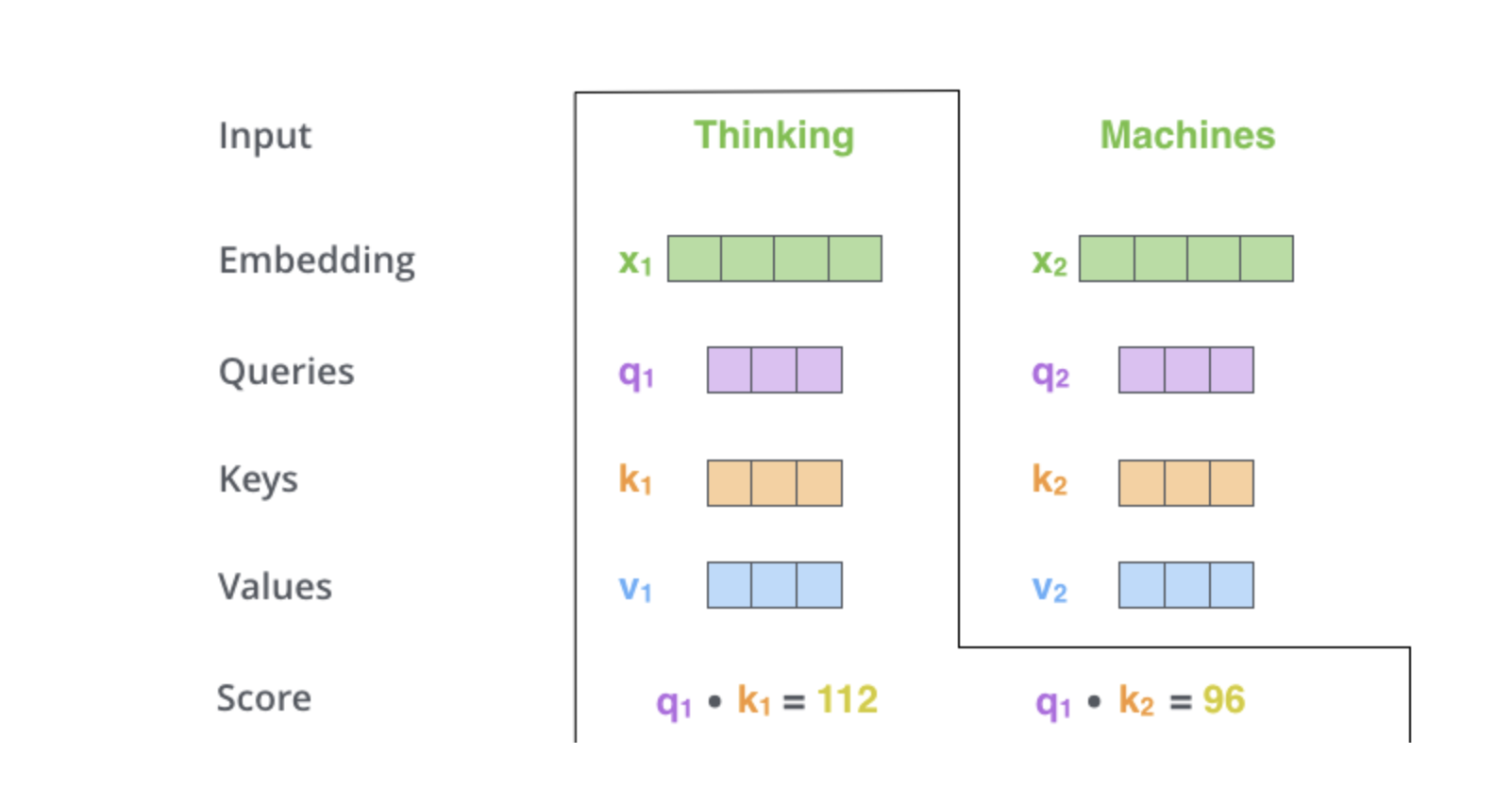
Step 2: Each word embedding is transformed using three weight matrices: Q, K, V:
\[
q_i = Q x_i \quad \text{(queries)}
\]
\[
k_i = K x_i \quad \text{(keys)}
\]
\[
v_i = V x_i \quad \text{(values)}
\]
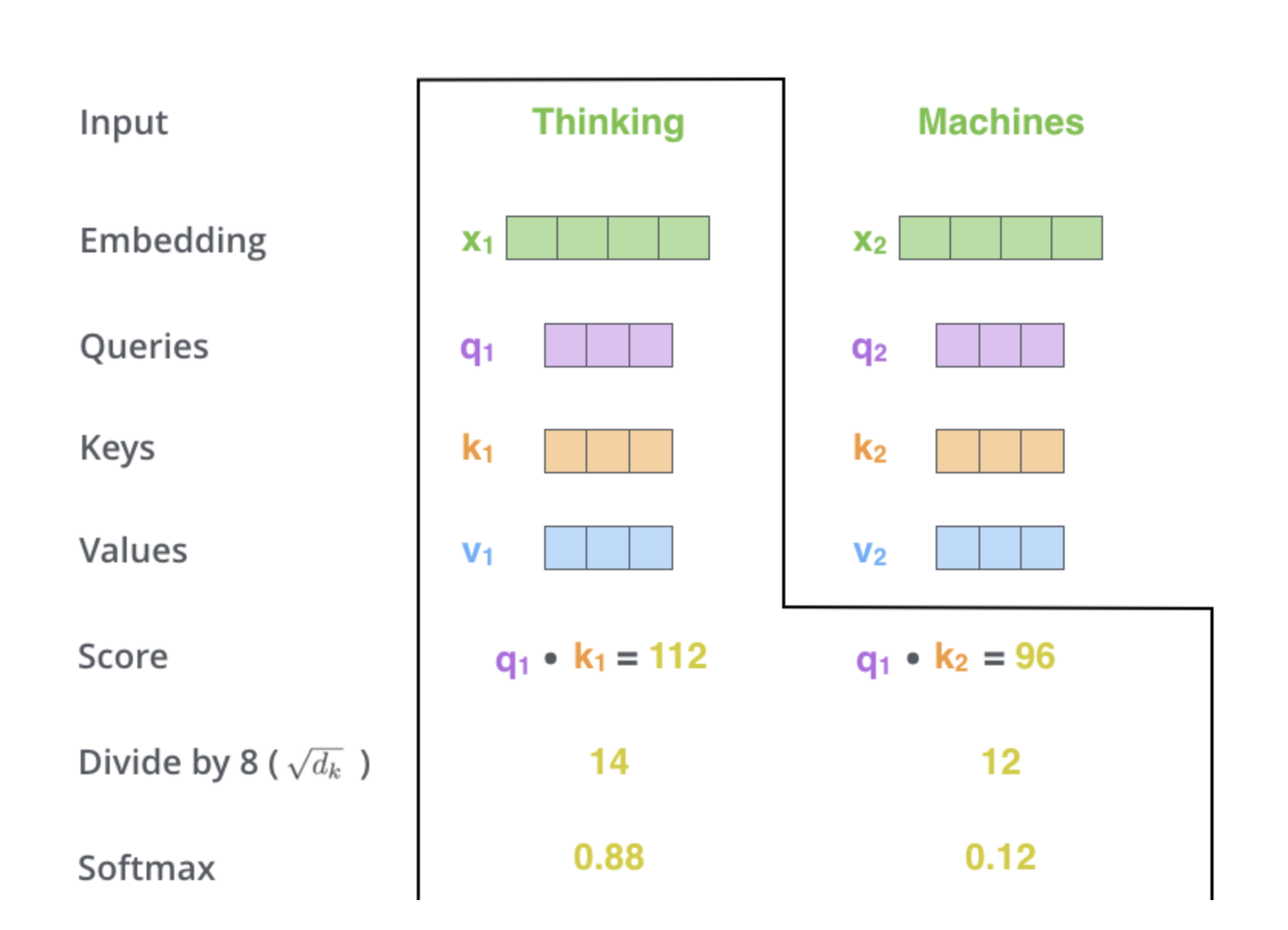
Step3: Compute pairwise similarities and normalize with softmax. Similarity between query (q_i) and key (k_j) as a simple dot product
\[
e_{ij} = q_i^{\top} k_j
\]
Attention weights:
\[
\alpha_{ij} =
\frac{\exp(e_{ij})}{\sum_{j'} \exp(e_{ij'})}
\]
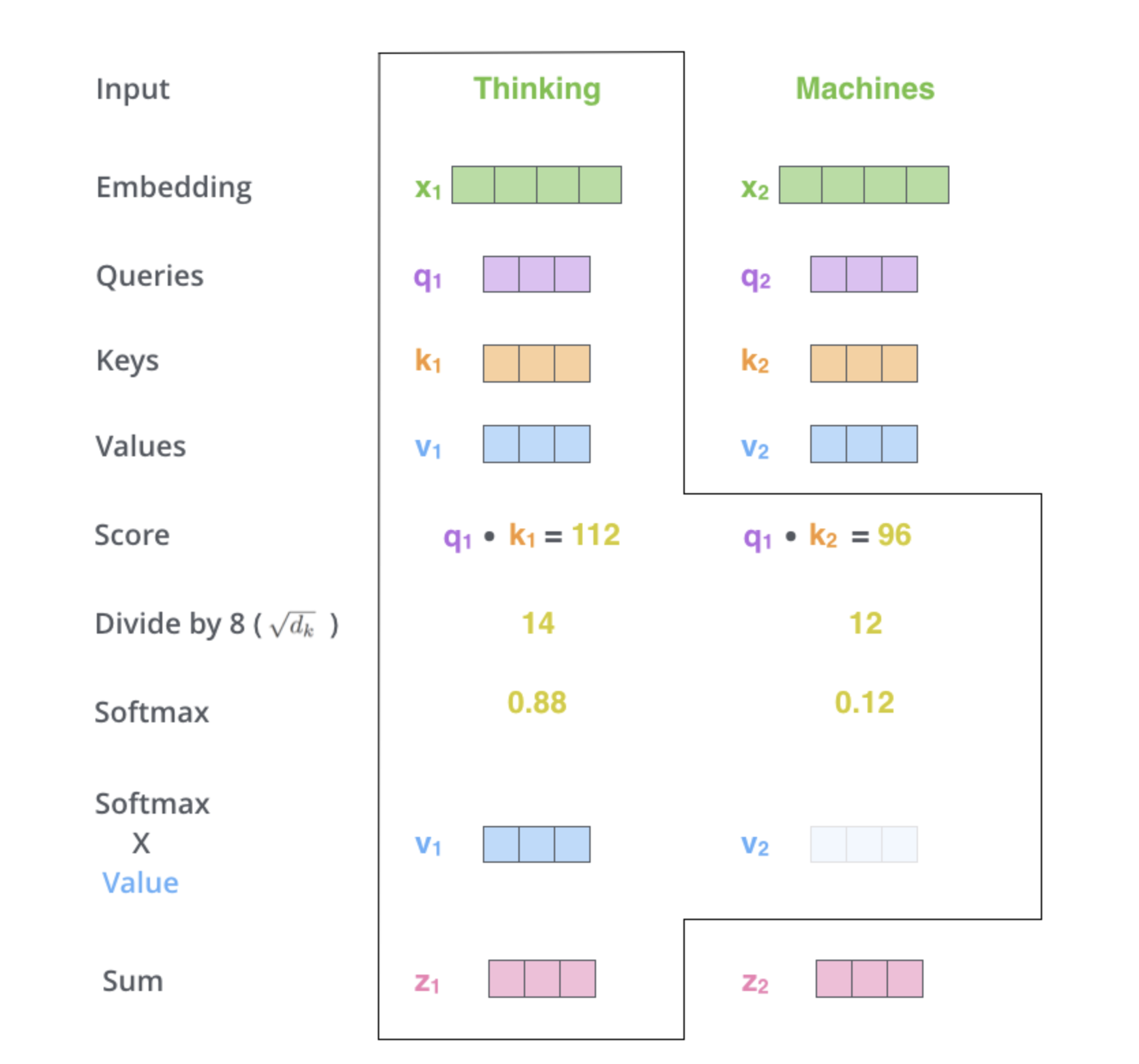
Step 4: Compute output as weighted sum of values
\[
o_i = \sum_j \alpha_{ij} v_j
\]