PPOL 6801 - Text as Data - Computational Linguistics
Week 10: Scaling Models for Text
Plans for Today:
Overview of scaling models
Scaling models using text
supervised models: wordscore
unsupervised models:
wordfish
Doc2vec
Scaling models with network data
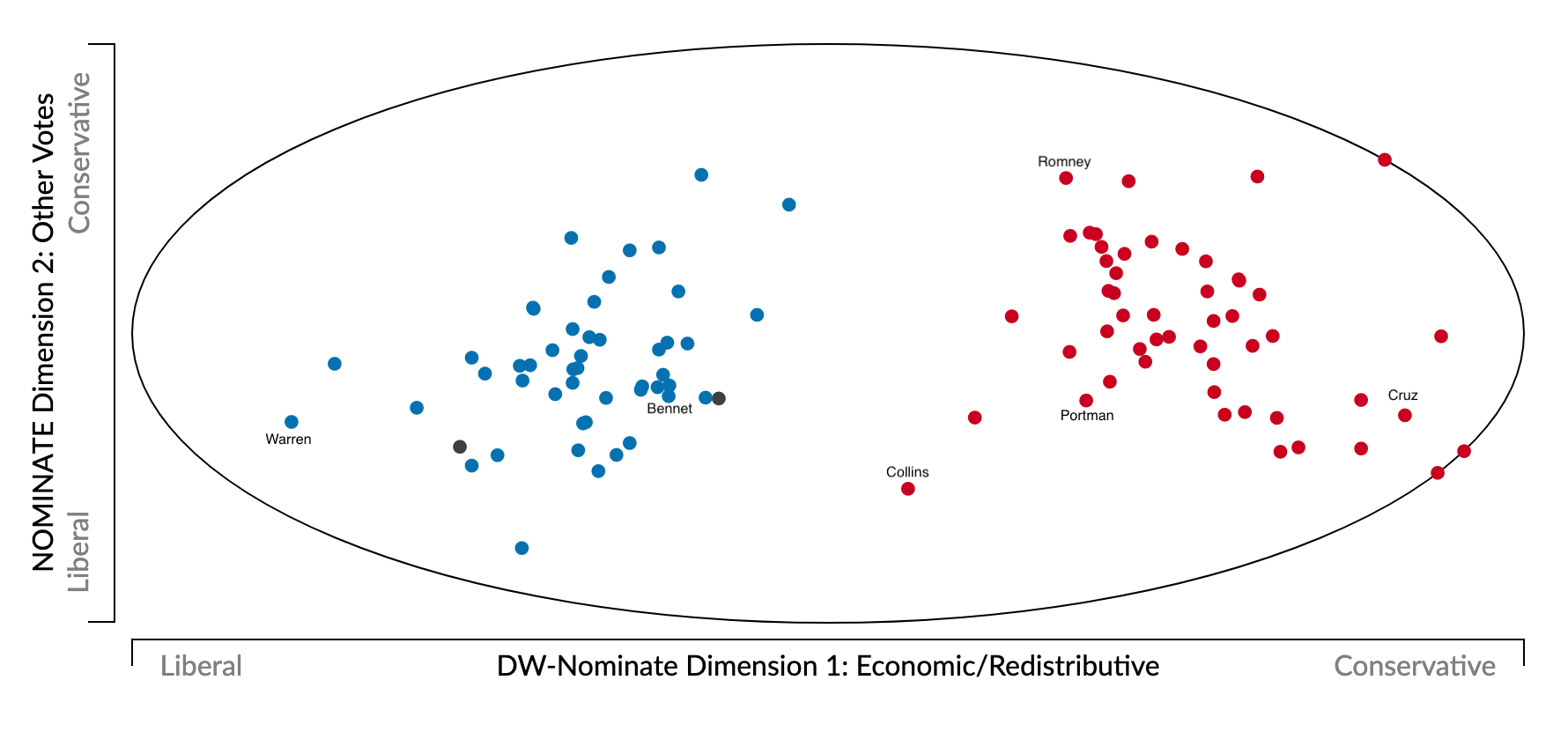
Many questions depends on policy positions
Many substantive questions in policy and politics depends on estimating ideological preferences:
- Is polarization increasing over time?
- are parties moving together over time?
- Do governments/coalitions last longer conditional on:
- how homogeneous coalition is?
- distance between coalition and congress ideal points?
- distance between coalition and median voter?
- Does ideology affect policy decisions?
- Economic Cycles and elections?
- globalization and the social welfare state?
Many more examples ….
Scaling with without computational text analysis
- Surveys
- Ask elites or regular voters about policy preference, and scale them in some sort of political continuum.
- Challenges:
- Expensive
- Sources of bias: non-response, social desirebility, strategic responses, to name a few
- Cannot be used for historical data
Scaling with without computational text analysis
- Behavioral data (for example, roll-call voting):
- Politicians vote on proposals (or judges make decisions) that are close to their ideal points
- Use statistical methods (mostly matrix factorization) to estimate orthogonal dimensions
- Nominate Scores
- Challenge
- Most times politicians vote for many things other than ideology
- Face-Validity: AOC for example often place as a centrist (not always voting with democrats)
- Politicians vote on proposals (or judges make decisions) that are close to their ideal points
Scaling with without computational text analysis
- Text Data
- Manually label content of political manifestos (Comparative Manifestos Project)
- Challenges:
- Really expensive
- Costly to translate to other languages
- Heavily dependent on substantive knowledge
Scaling models with computational text analysis
In the past 20 years, computational text analysis has been widely used for building scaling models.
Advantages: fast, reliable, deals with large volumes of text, and easy to translate to other domains/language.
Wordscore: supervised approach, mimic naive bayesian models, start with reference, and score virgin texts.
Wordfish: unsupervised approach, learn word occurrence from the documents using a ideal points models.
Doc2Vec: unsupervised approach, maps documents in the embedding vector space, use PCA to reduce dimensionality.
Wordscore
Step 1: Begin with a reference set (training set) of texts that have known positions.
- get a speech by AOC , give it -1 score.
- get a speech by MTG, give it a +1 score.
Step 2: Generate word scores from these reference texts
- Pretty much like a NB
Step 3: Score the virgin texts (test set) of texts using those word scores
- scale virgin score to the same original metric (-1 to +1)
- calculate confidence intervals
Scoring Words
Learning Words
\[ P_{wr} = \frac{F_{wr}}{\sum_r F_{wr}}\] - \(P_{wr}\): Probability of word \(w\) being from reference document \(r\)
- \(F_{wr}\): Frequency of word \(w\) in reference text \(r\)
Scoring Words
\[S_{wd} = \sum_r (P_{wr} \cdot A_{rd}) \] - \(S_{wd}\): Score of word \(w\) in dimension \(d\)
\(A_{rd}\): Pre-defined position of reference text \(r\) in dimension \(d\)
\(A_{rd}\) will be -1 for liberal and +1 for conservative documents, for example.
Scoring virgin texts
\[ S_{vd} = \sum_w (F_{wv} · S_{wd}) \]
Example
Republican manifesto uses `wall’ 25 times in 1000 words, while Democrat use it only 5 times. Assume 1 for republican and -1 for democrat
\[P_{wr} = 0.83\]
\[P_{wl} = 0.16 \] \[ S_w = 0.83*1 + -1*.16 = 0.66\]
Virgin text 1 mentions wall 200 times in 1000 words ~ \(0.2 * 0.66 = 0.132\)
Virgin text 2 mentions wall 1 times in 1000 words ~ \(0.001 * 0:66 = 0.0066\)
Repeat for all words!
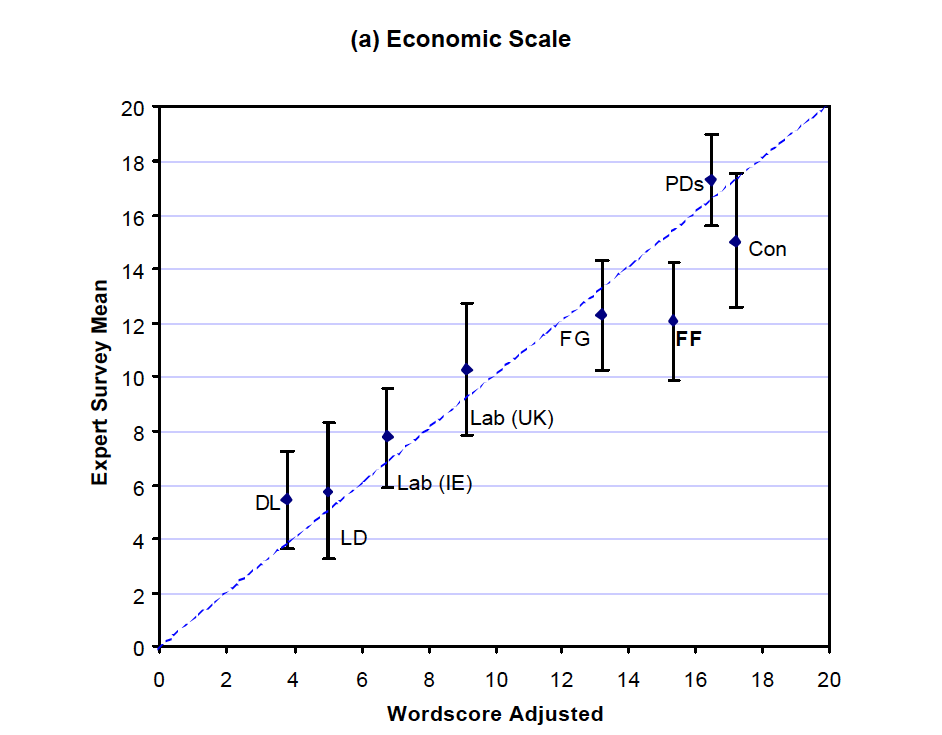
Results
Text-as-Data