![]()
PPOL 5203 - Data Science I: Foundations
Week 11: Text-As-Data II: Classification
Professor: Tiago Ventura
Plans for Today
- Supervised Learning with Text
- Dictionary Methods
- Machine Learning
- Transformers: Pre-Trained Models
- Coding
- Topics Models
- Supervised learning
In three weeks: Project Presentations. Your final project in slides!
Supervised Learning
What is Supervised Learning?
Def: machine learning algorithm type that requires labeled input data to understand the mapping function from the input to the output
SUPERVISED: The true labels y act as a “supervisor” for the learning process
- Model predicts ˆy for each input x
- Compare predictions ˆy to true labels y
- Adjust model to minimize errors
LEARNING: the process by which a machine/model improves its performance on a specific task
Supervised Learning with Text
When doing supervised learning with text, we have three basic pieces of the puzzle:
Outcome: the class you want to classify.
- Examples:
- Tone, Emotion, Topic, Misinformation, Quality… Anything you know what you want to classify
- Examples:
Input: this is your text. Often as a Document Feature Matrix.
Model: An transformation function connecting your words with the outcome you want to predict.
Three types of Supervised Learning with Text
In class, we will see three distinct types of approaches to do supervised learning with text.
Dictionary Models.
Classic Machine Learning with bag-of-words assumption.
Pre-Trained Models Deep Learning Models.
Plus: Prompting Large Language Models (Full class next week)
Dictionary Models
Use a set of pre-defined words that allow us to classify documents automatically, quickly and accurately.
Instead of optimizing a transformation function using statistical assumption and seen data, in dictionaries we have a pre-assumed recipe for the transformation function.
A dictionary contains:
- a list of words that corresponds to each category
- positive and negative for sentiment
- Sexism, homophobia, xenophobia, racism for hate speech
- a list of words that corresponds to each category
Weights given to each word ~ same for all words or some continuous variation.
More specifically…
We have a set of key words with weights,
e.g. for sentiment analysis: horrible is scored as \(-1\) and beautiful as \(+1\)
the relative rate of occurrence of these terms tells us about the overall tone or category that the document should be placed in.
For document \(i\) and words \(m=1,\ldots, M\) in the dictionary,
\[\text{tone of document $i$}= \sum^M_{m=1} \frac{s_m w_{im}}{N_i}\]
Where:
- \(s_m\) is the score of word \(m\)
- \(w_{im}\) is the number of occurrences of the \(m_{th}\) dictionary word in the document \(i\)
- \(N_i\) is the total number of all dictionary words in the document
Quizz. Advantages and Disadvantages of dictionaries?
Classic Machine Learning with bag-of-words assumption.
Pipeline:
Step 1: label some examples of the concept of we want to measure (output)
Step 2: convert your data to a document-feature matrix (input)
Step 3: train a statistical model on these set of label data using the document-feature matrix.
Step 4: use the classifier - some f(x) - to predict unseen documents
How to obtain a training labeled dataset?
External Source of Annotation: Someone else labelled the data for you
- Federalist papers
- Metadata from text
- Manifestos from Parties with well-developed dictionaries
Expert annotation:
- mostly undergrads ~ that you train to be experts
Crowd-sourced coding: digital labor markets
- Wisdom of Crowds: the idea that large groups of non-expert people are collectively smarter than individual experts when it comes to problem-solving
Evaluating the Performance
| Predicted | ||||
|---|---|---|---|---|
| J | ¬J | Total | ||
| Actual | J | a (True Positive) | b (False Negative) | a+b |
| ¬J | c (False Positive) | d (True Negative) | c+d | |
| Total | a+c | b+d | N |
Accuracy: number correctly classified/total number of cases = (a+d)/(a+b+c+d)
Precision : number of TP / (number of TP+number of FP) = a/(a+c) .
- Fraction of the documents predicted to be J, that were in fact J.
- Think as a measure for the estimator (Very precise estimate)
Recall: (number of TP) / (number of TP + number of FN) = a /(a+b)
- Fraction of the documents that were in fact J, that method predicted were J.
- Think as a measure for the data (Covers most of the cases in the data)
F : 2 precision*recall / precision+recall
- Harmonic mean of precision and recall.
Quizz. Advantages and Disadvantages of Classic ML?
Pre-Trained Deep Learning Models
In recent years, text-as-data/nlp tasks have been dominated by the use of deep learning models. Let’s try to understand a bit what these models are.
Components: These deep learning models have two major components
- A dense representation of words (no bag of words!).
- Every word becomes a vector now
- A deep architecture for model predictions ~ neural network
- A dense representation of words (no bag of words!).
Definition: Deep Learning Models are designed for general-purpose classification tasks or just simple next-word prediction tasks (language modelling)
- In general those are models built on TONS of data and optimized for a particular task
Key Features:
- Available for use, adaptation and experimentation
- Ready to use
- Low to zero cost
- Deep ML architectures ~ High accuracy
- Can be fine-tuned for your specific task
Dense Vector Representation
In the vector space model, we learned:
A document \(D_i\) is represented as a collection of features \(W\) (words, tokens, n-grams..)
Each feature \(w_i\) can be place in a real line, then a document \(D_i\) is a point in a \(W\) dimensional space.
Embedded in this model, there is the idea we represent words as a one-hot encoding.
- “cat”: [0,0, 0, 0, 0, 0, 1, 0, ….., V] , on a V dimensional vector
- “dog”: [0,0, 0, 0, 0, 0, 0, 1, …., V], on a V dimensional vector
Sparse vs Dense Vectors
One-hot encoding / Sparse Representation:
cat = \(\begin{bmatrix} 0,0, 0, 0, 0, 0, 1, 0, 0 \end{bmatrix}\)
dog = \(\begin{bmatrix} 0,0, 0, 0, 0, 1, 0, 0, 0 \end{bmatrix}\)
Word Embedding / Dense Representation:
cat = \(\begin{bmatrix} 0.25, -0.75, 0.90, 0.12, -0.50, 0.33, 0.66, -0.88, 0.10, -0.45 \end{bmatrix}\)
dog = \(\begin{bmatrix} 0.25, 1.75, 0.90, 0.12, -0.50, 0.33, 0.66, -0.88, 0.10, -0.45 \end{bmatrix}\)
Dense representations are behind all recent advancements on NLP, including ChatGPT
Embeddings with Self-Supervision
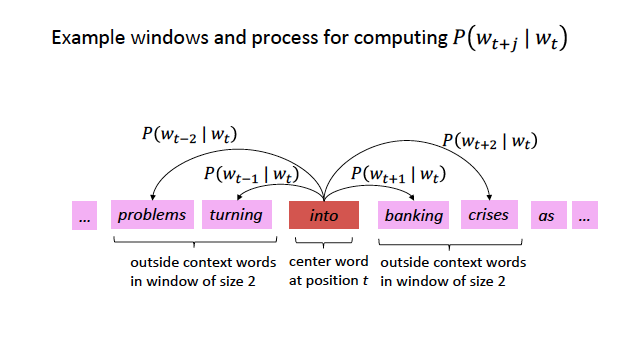
Source: CS224N
Transformer architeture
Transformer History
The transformer architecture was introduced only in 2017!! This paper revolutionized many natural language processing tasks, particularly, machine translation and language modelling. All famous models LLMs of today are based in the transformers framework
How do I use these sophisticated models?
If you have enough computing power and knowledge of working with these models, you can train your own LLM models. It takes a LOT of data, time and money. Only big tech companies can actually do this
So, you will very likely:
use pre-trained models available on the web (Google Perspective)
use pre-trained transformers, fine tune the model (retrain with new data), and improve the performance of the models
Or outsource tasks for generative models through prompting via APIs.
Hugging Face for Transformers
Hugging Face’s Model Hub: centralized repository for sharing and discovering pre-trained models [https://huggingface.co]
Coding!
Data science I: Foundations