class: center, middle, title-slide .title[ # Collecting and Analyzing Social Media Data<br> ] .author[ ### Tiago Ventura | Center for Social Media and Politics | NYU ] .date[ ### <span style="font-size: 70%;"> Big Data for Development and Governance <br> 10/21/2022 </span> ] --- name: about-me layout: false class: about-me-slide, inverse, middle, center ## .red[About me] <img style="border-radius: 40%;" src="./figs/tiago.jpg" width="150px"/> ### Tiago Ventura ### Postdoc at Center for Social Media and Politics, NYU .fade[Incoming Assistant Professor, McCourt School, Georgetown University] [<svg role="img" viewBox="0 0 24 24" style="height:1em;position:relative;display:inline-block;top:.1em;" xmlns="http://www.w3.org/2000/svg"> <title></title> <path d="M23.953 4.57a10 10 0 01-2.825.775 4.958 4.958 0 002.163-2.723c-.951.555-2.005.959-3.127 1.184a4.92 4.92 0 00-8.384 4.482C7.69 8.095 4.067 6.13 1.64 3.162a4.822 4.822 0 00-.666 2.475c0 1.71.87 3.213 2.188 4.096a4.904 4.904 0 01-2.228-.616v.06a4.923 4.923 0 003.946 4.827 4.996 4.996 0 01-2.212.085 4.936 4.936 0 004.604 3.417 9.867 9.867 0 01-6.102 2.105c-.39 0-.779-.023-1.17-.067a13.995 13.995 0 007.557 2.209c9.053 0 13.998-7.496 13.998-13.985 0-.21 0-.42-.015-.63A9.935 9.935 0 0024 4.59z"></path></svg> @TiagoVentura_](https://twitter.com/_Tiagoventura) [<svg role="img" viewBox="0 0 24 24" style="height:1em;position:relative;display:inline-block;top:.1em;" xmlns="http://www.w3.org/2000/svg"> <title></title> <path d="M12 .297c-6.63 0-12 5.373-12 12 0 5.303 3.438 9.8 8.205 11.385.6.113.82-.258.82-.577 0-.285-.01-1.04-.015-2.04-3.338.724-4.042-1.61-4.042-1.61C4.422 18.07 3.633 17.7 3.633 17.7c-1.087-.744.084-.729.084-.729 1.205.084 1.838 1.236 1.838 1.236 1.07 1.835 2.809 1.305 3.495.998.108-.776.417-1.305.76-1.605-2.665-.3-5.466-1.332-5.466-5.93 0-1.31.465-2.38 1.235-3.22-.135-.303-.54-1.523.105-3.176 0 0 1.005-.322 3.3 1.23.96-.267 1.98-.399 3-.405 1.02.006 2.04.138 3 .405 2.28-1.552 3.285-1.23 3.285-1.23.645 1.653.24 2.873.12 3.176.765.84 1.23 1.91 1.23 3.22 0 4.61-2.805 5.625-5.475 5.92.42.36.81 1.096.81 2.22 0 1.606-.015 2.896-.015 3.286 0 .315.21.69.825.57C20.565 22.092 24 17.592 24 12.297c0-6.627-5.373-12-12-12"></path></svg> TiagoVentura](https://github.com/TiagoVentura) [<svg viewBox="0 0 512 512" style="height:1em;position:relative;display:inline-block;top:.1em;" xmlns="http://www.w3.org/2000/svg"> <title></title> <path d="M424,80H88a56.06,56.06,0,0,0-56,56V376a56.06,56.06,0,0,0,56,56H424a56.06,56.06,0,0,0,56-56V136A56.06,56.06,0,0,0,424,80Zm-14.18,92.63-144,112a16,16,0,0,1-19.64,0l-144-112a16,16,0,1,1,19.64-25.26L256,251.73,390.18,147.37a16,16,0,0,1,19.64,25.26Z"></path></svg> venturat@umd.edu](venturat@umd.edu) [<svg viewBox="0 0 512 512" style="height:1em;position:relative;display:inline-block;top:.1em;" xmlns="http://www.w3.org/2000/svg"> <title></title> <path d="M208,352H144a96,96,0,0,1,0-192h64" style="fill:none;stroke:#000;stroke-linecap:round;stroke-linejoin:round;stroke-width:36px"></path> <path d="M304,160h64a96,96,0,0,1,0,192H304" style="fill:none;stroke:#000;stroke-linecap:round;stroke-linejoin:round;stroke-width:36px"></path> <line x1="163.29" y1="256" x2="350.71" y2="256" style="fill:none;stroke:#000;stroke-linecap:round;stroke-linejoin:round;stroke-width:36px"></line></svg>https://tiagoventura.rbind.io/](https://venturatiago.com/) --- class:middle ## Plans for the Workshop -- #### Twitter Data - Collecting data using the Academic Access through [academictwitteR](https://github.com/cjbarrie/academictwitteR). - Quick introduction to network analysis with Twitter data -- #### Youtube Data. - [Python Library](https://youtube-data-api.readthedocs.io/en/latest/youtube_api.html) developed by Megan Brown, Senior Engenieer at the Center for Social Media and Politics at NYU, and some other colleagues. -- #### Telegram Data - [Python module Telethon](https://docs.telethon.dev/en/stable/index.html). --- class: middle # One-hour workshop .center[ <img src="figs/gif.gif" width="50%" /> ] --- class: middle # Some assumptions -- - Assume some knowledge of R and Python. -- - We will not go through authentication with the APIs (instructions are provided for you to go through it later). -- - You can follow the code in the notebooks. However, the best approach is just to run this later by yourselve, with the proper access to the APIs. -- - Particularly for Youtube and Telegram, I will just showcase others' people library to access data from these platforms. -- --- class:middle ## Logistics All materials are available in the Github repo for the workshop: [https://github.com/TiagoVentura/workshop_big_data_conference](https://github.com/TiagoVentura/workshop_big_data_conference). You can just clone all the files from there. More: - Slides: [Twitter](https://tiagoventura.github.io/workshop_big_data_conference/presentation_workshop_twitter.html), [Youtube](https://tiagoventura.github.io/workshop_big_data_conference/presentation_workshop_youtube.html), [Telegram](https://tiagoventura.github.io/workshop_big_data_conference/presentation_workshop_telegram.html) - Notebooks: [Twitter](https://tiagoventura.github.io/workshop_big_data_conference/notebook_twitter.html), [Youtube](https://tiagoventura.github.io/workshop_big_data_conference/notebook_youtube.html), [Telegram](https://tiagoventura.github.io/workshop_big_data_conference/notebook_telegram.html) --- class:inverse, middle # Gathering and Analyzing Twitter Data --- class:middle ## Getting Access to the Twitter APIs. -- -- - [Apply for a Twitter developer account](https://developer.twitter.com/en/apply-for-access). -- - [Apply to the academic research product track](https://developer.twitter.com/en/portal/petition/academic/is-it-right-for-you). -- - Save your keys in a local file in your computer. -- --- class:middle ## Standard Access - Search for Tweets from the last 7 days. - Stream Tweets in real-time - Get Tweets from a user’s timeline (up to 3200 most recent Tweets) - Build the full Tweet objects from a Tweet ID, or a set of Tweet IDs - Look up follower relationships --- class:middle ## Academic Research product track - Ability to get historical Tweets. - Cap of 10 million Tweets per month - More advanced filter options to return relevant data. --- class:middle ## Collecting Twitter Data -- - **For R users:** [academictwitteR](https://github.com/cjbarrie/academictwitteR) package developed by Chris Barrie. - **For Python User:** check the library [Twarc](https://twarc-project.readthedocs.io/en/latest/). --- ## Access tweets from the archive #### Load Packages ```r # Call packages using pacman #install.packages("pacman") pacman::p_load(here, jsonlite, tidyverse, academictwitteR) ``` #### Add your API Key ```r # Using Academic Twitter to add yourkey *set_bearer() ``` --- class:middle ## get_all_tweets ```r # Using Academic Twitter to add yourkey # Collect data tweets <- get_all_tweets( * query = "(eleicoes2022 OR lula OR bolsonaro OR ciro OR tebet)", start_tweets = "2022-10-01T00:00:00Z", #start time end_tweets = "2022-10-04T00:00:00Z", #end time file = "br_elections", # file to save data_path = "data_br/", # folder where all data as jsons will be stores n = 200000, # number of tweets lang = "pt" ) ``` --- class:middle ## get_all_tweets ```r # Using Academic Twitter to add yourkey # Collect data tweets <- get_all_tweets( query = "(eleicoes2022 OR lula OR bolsonaro OR ciro OR tebet)", * start_tweets = "2022-10-01T00:00:00Z", #start time * end_tweets = "2022-10-04T00:00:00Z", #end time file = "br_elections", # file to save data_path = "data_br/", # folder where all data as jsons will be stores n = 200000, # number of tweets lang = "pt" ) ``` --- class:middle ## get_all_tweets ```r # Using Academic Twitter to add yourkey # Collect data tweets <- get_all_tweets( query = "(eleicoes2022 OR lula OR bolsonaro OR ciro OR tebet)", start_tweets = "2022-10-01T00:00:00Z", #start time end_tweets = "2022-10-04T00:00:00Z", #end time file = "br_elections", * data_path = "data_br/", n = 200000, # number of tweets lang = "pt" ) ``` --- class:middle ## get_all_tweets ```r # Using Academic Twitter to add yourkey # Collect data tweets <- get_all_tweets( query = "(eleicoes2022 OR lula OR bolsonaro OR ciro OR tebet)", start_tweets = "2022-10-01T00:00:00Z", #start time end_tweets = "2022-10-04T00:00:00Z", #end time file = "br_elections", # file to save data_path = "data_br/", # folder where all data as jsons will be stores * n = 200000, lang = "pt" ) ``` --- ## Where does the data live? .center[ <img src="figs/data_tw.png" width="80%" /> ] --- ## bind_tweets: tidy ```r # data processing *tweets_tidy <- bind_tweets("./data_br", output_format = "tidy") tweets_tidy ``` ``` ## # A tibble: 6 × 31 ## tweet_id user_…¹ text possi…² conve…³ lang source creat…⁴ autho…⁵ in_re…⁶ ## <chr> <chr> <chr> <lgl> <chr> <chr> <chr> <chr> <chr> <chr> ## 1 1577066499… cainsw… "RT … FALSE 157706… pt Twitt… 2022-1… 809471… <NA> ## 2 1577066498… nandam… "RT … FALSE 157706… pt Twitt… 2022-1… 422691… <NA> ## 3 1577066498… fran51… "RT … FALSE 157706… pt Twitt… 2022-1… 133561… <NA> ## 4 1577066498… juliam… "RT … FALSE 157706… pt Twitt… 2022-1… 839520… <NA> ## 5 1577066497… Comerc… "@Au… FALSE 157706… pt Twitt… 2022-1… 155826… 152441… ## 6 1577066497… caralh… "RT … FALSE 157706… pt Twitt… 2022-1… 136448… <NA> ## # … with 21 more variables: user_name <chr>, user_created_at <chr>, ## # user_location <chr>, user_verified <lgl>, user_description <chr>, ## # user_protected <lgl>, user_pinned_tweet_id <chr>, ## # user_profile_image_url <chr>, user_url <chr>, retweet_count <int>, ## # like_count <int>, quote_count <int>, user_tweet_count <int>, ## # user_list_count <int>, user_followers_count <int>, ## # user_following_count <int>, sourcetweet_type <chr>, sourcetweet_id <chr>, … ## # ℹ Use `colnames()` to see all variable names ``` --- ## bind_tweets: json ```r # examing the data tweets_raw <- bind_tweets("./data_br", * output_format = "raw") str(tweets_raw, max.level=1) ``` ``` ## List of 27 ## $ tweet.entities.mentions : tibble [215,630 × 5] (S3: tbl_df/tbl/data.frame) ## $ tweet.entities.annotations : tibble [386,283 × 6] (S3: tbl_df/tbl/data.frame) ## $ tweet.entities.urls : tibble [32,703 × 12] (S3: tbl_df/tbl/data.frame) ## $ tweet.entities.hashtags : tibble [10,405 × 4] (S3: tbl_df/tbl/data.frame) ## $ tweet.entities.cashtags : tibble [3 × 4] (S3: tbl_df/tbl/data.frame) ## $ tweet.public_metrics.retweet_count : tibble [200,062 × 2] (S3: tbl_df/tbl/data.frame) ## $ tweet.public_metrics.reply_count : tibble [200,062 × 2] (S3: tbl_df/tbl/data.frame) ## $ tweet.public_metrics.like_count : tibble [200,062 × 2] (S3: tbl_df/tbl/data.frame) ## $ tweet.public_metrics.quote_count : tibble [200,062 × 2] (S3: tbl_df/tbl/data.frame) ## $ tweet.attachments.media_keys : tibble [200,062 × 2] (S3: tbl_df/tbl/data.frame) ## $ tweet.attachments.poll_ids : tibble [200,062 × 2] (S3: tbl_df/tbl/data.frame) ## $ tweet.geo.place_id : tibble [200,062 × 2] (S3: tbl_df/tbl/data.frame) ## $ tweet.geo.coordinates : tibble [200,062 × 3] (S3: tbl_df/tbl/data.frame) ## $ tweet.withheld.country_codes : tibble [200,062 × 2] (S3: tbl_df/tbl/data.frame) ## $ tweet.withheld.copyright : tibble [200,062 × 2] (S3: tbl_df/tbl/data.frame) ## $ tweet.edit_history_tweet_ids : tibble [200,062 × 2] (S3: tbl_df/tbl/data.frame) ## $ tweet.referenced_tweets : tibble [184,799 × 3] (S3: tbl_df/tbl/data.frame) ## $ tweet.main :'data.frame': 200062 obs. of 9 variables: ## $ user.public_metrics.followers_count: tibble [337,098 × 2] (S3: tbl_df/tbl/data.frame) ## $ user.public_metrics.following_count: tibble [337,098 × 2] (S3: tbl_df/tbl/data.frame) ## $ user.public_metrics.tweet_count : tibble [337,098 × 2] (S3: tbl_df/tbl/data.frame) ## $ user.public_metrics.listed_count : tibble [337,098 × 2] (S3: tbl_df/tbl/data.frame) ## $ user.entities.url : tibble [337,098 × 2] (S3: tbl_df/tbl/data.frame) ## $ user.entities.description : tibble [337,098 × 5] (S3: tbl_df/tbl/data.frame) ## $ user.withheld.country_codes : tibble [337,098 × 2] (S3: tbl_df/tbl/data.frame) ## $ user.main :'data.frame': 337098 obs. of 11 variables: ## $ sourcetweet.main :'data.frame': 132813 obs. of 16 variables: ``` --- class:middle ## Network Analysis with Twitter Data Many different ways you can analyze Twitter data: the text, the images, the geolocation, links, among many other things. A popular way is to to look at the user connections using some sort of network models. Not limited to Twitter data. A network has two core elements: nodes and edges. On Twitter this means: - Nodes are Twitter users - Edges are any sort of connections these users make. A reply, a friendship, or the most common, a retweet. [igraph](https://igraph.org/r/) package to analyze network data in R. --- class:middle, inverse ## Intro to Network Analysis in R --- ### Step 1: Filter Nodes .panelset[ .panel[.panel-name[Code] ```r # Filter retweets tweets_tidy_rt <- tweets_tidy %>% * filter(!is.na(sourcetweet_type)) # Visualize the dta tweets_tidy_rt %>% select(user_username, sourcetweet_author_id) %>% head() ``` ] .panel[.panel-name[Output] ``` ## # A tibble: 6 × 2 ## user_username sourcetweet_author_id ## <chr> <chr> ## 1 cainsworts 1534722153819643906 ## 2 nandamattosbh 18880621 ## 3 fran51995877 26752656 ## 4 juliam3ndes 863806721696858112 ## 5 caralho_modesti 2876592790 ## 6 carolfcarneiro 44481447 ``` ] ] --- ## Step 2: Create a edge list .panelset[ .panel[.panel-name[Code] ```r # Create a edge list *data <- cbind(tweets_tidy_rt$author_id, * tweets_tidy_rt$sourcetweet_author_id) ``` ] .panel[.panel-name[Output] ``` ## [,1] [,2] ## [1,] "809471355116781568" "1534722153819643906" ## [2,] "42269111" "18880621" ## [3,] "1335618427852124163" "26752656" ## [4,] "839520909807521793" "863806721696858112" ## [5,] "136448124" "2876592790" ## [6,] "108719485" "44481447" ``` ] ] --- ## Step 3: Create your network structure .panelset[ .panel[.panel-name[Code] ```r pacman::p_load(igraph) # Create an empty network *net <- graph.empty() # Add nodes net <- add.vertices(net, length(unique(c(data))), # number of nodes name=as.character(unique(c(data)))) # unique names # Add edges net <- add.edges(net, t(data)) # summary summary(net) ``` ] ] --- ## Step 3: Create your network structure .panelset[ .panel[.panel-name[Code] ```r pacman::p_load(igraph) # Create an empty network net <- graph.empty() # Add nodes *net <- add.vertices(net, * length(unique(c(data))), # number of nodes * name=as.character(unique(c(data)))) # unique names # Add edges net <- add.edges(net, t(data)) # summary summary(net) ``` ] ] --- ## Step 3: Create your network structure .panelset[ .panel[.panel-name[Code] ```r pacman::p_load(igraph) # Create an empty network net <- graph.empty() # Add nodes net <- add.vertices(net, length(unique(c(data))), # number of nodes name=as.character(unique(c(data)))) # unique names # Add edges *net <- add.edges(net, t(data)) # summary summary(net) ``` ] .panel[.panel-name[Output] ``` ## IGRAPH 4cfb9d2 DN-- 79886 154583 -- ## + attr: name (v/c) ``` ] ] --- ## Step four: Add information to your network object Edge level (`E(object)`) or Node leve (`V(object)`). .panelset[ .panel[.panel-name[Code] ```r library(urltools) # Edges *E(net)$text <- tweets_tidy_rt$text *E(net)$idauth <- tweets_tidy_rt$sourcetweet_author_id *E(net)$namehub <- tweets_tidy_rt$user_username # Capturing hashtags E(net)$hash <- str_extract_all(tweets_tidy_rt$text, "#\\S+") ``` ] .panel[.panel-name[Accessing the raw] ```r # grab expanded and unwound_url *entities <- tweets_raw$tweet.entities.urls entities ``` ``` ## # A tibble: 32,703 × 12 ## tweet…¹ start end url expan…² displ…³ media…⁴ images status title descr…⁵ ## <chr> <int> <int> <chr> <chr> <chr> <chr> <list> <int> <chr> <chr> ## 1 157706… 73 96 http… https:… pic.tw… 7_1507… <NULL> NA <NA> <NA> ## 2 157706… 56 79 http… https:… pic.tw… 7_1577… <NULL> NA <NA> <NA> ## 3 157706… 75 98 http… https:… notici… <NA> <df> 200 Perf… Com vi… ## 4 157706… 77 100 http… https:… twitte… <NA> <NULL> NA <NA> <NA> ## 5 157706… 62 85 http… https:… revist… <NA> <NULL> 200 Zema… Govern… ## 6 157706… 99 122 http… https:… pic.tw… 7_1577… <NULL> NA <NA> <NA> ## 7 157706… 33 56 http… https:… pic.tw… 3_1577… <NULL> NA <NA> <NA> ## 8 157706… 87 110 http… https:… pic.tw… 7_1558… <NULL> NA <NA> <NA> ## 9 157706… 95 118 http… https:… uol.pa… <NA> <df> 200 Perf… Com vi… ## 10 157706… 243 266 http… https:… twitte… <NA> <NULL> NA <NA> <NA> ## # … with 32,693 more rows, 1 more variable: unwound_url <chr>, and abbreviated ## # variable names ¹tweet_id, ²expanded_url, ³display_url, ⁴media_key, ## # ⁵description ## # ℹ Use `print(n = ...)` to see more rows, and `colnames()` to see all variable names ``` ] .panel[.panel-name[Capturing Domains] ```r ## Capturing domains tidy_entities <- entities %>% # get columns we need select(tweet_id, unwound_url) %>% #extract domains mutate(unwound_url=domain(unwound_url)) %>% # remove nas and # combine multiple links filter(!is.na(unwound_url)) %>% group_by(tweet_id) %>% * summarise(domain=paste0(unwound_url, collapse=" -- ")) # Merge back with id tweets_tidy_rt <- left_join(tweets_tidy_rt, tidy_entities) # add to the network *E(net)$domain <- tweets_tidy_rt$domain ``` ] .panel[.panel-name[Domains] ```r tweets_tidy_rt %>% janitor::tabyl(domain) %>% * arrange(desc(n)) %>% drop_na(domain) %>% slice(1:10) ``` ``` ## domain n percent valid_percent ## www.gazetadopovo.com.br 879 0.005686266 0.12913178 ## noticias.uol.com.br 826 0.005343408 0.12134567 ## revistaoeste.com 694 0.004489498 0.10195387 ## veja.abril.com.br 603 0.003900817 0.08858528 ## terrabrasilnoticias.com 562 0.003635587 0.08256207 ## gazetabrasil.com.br 521 0.003370358 0.07653886 ## www.brasil247.com 505 0.003266853 0.07418834 ## twitter.com 216 0.001397308 0.03173204 ## www.cnnbrasil.com.br 214 0.001384370 0.03143823 ## www1.folha.uol.com.br 213 0.001377901 0.03129132 ``` ] .panel[.panel-name[Output] ``` ## IGRAPH 4cfb9d2 DN-- 79886 154583 -- ## + attr: name (v/c), text (e/c), idauth (e/c), namehub (e/c), hash ## | (e/x), domain (e/c) ``` ] ] --- class: middle ## Network Statistics, Communities and Layout Two very common concepts in network science are in-degree and out-degree. - In-degree refers to how many links pointing to themselves the user has. - Out-degree means how many edges originated at this user. A user is called an authority when their in-degree is high. - A user is called a hub when its out-degree is high, as this user retweets very often. --- class: middle ## Degree Statistics ```r # Calculate in degree and out degree *V(net)$outdegree<-degree(net, mode="out") *V(net)$indegree<-degree(net, mode="in") summary(net) ``` ``` ## IGRAPH 4cfb9d2 DN-- 79886 154583 -- ## + attr: name (v/c), outdegree (v/n), indegree (v/n), text (e/c), idauth ## | (e/c), namehub (e/c), hash (e/x), domain (e/c) ``` --- class: middle ### Layout ```r *l <- layout_with_fr(net, grid = c("nogrid")) #saveRDS(l, "layout.rds") head(l) ``` ``` ## [,1] [,2] ## [1,] -102.96401 216.91269 ## [2,] -178.82523 158.25089 ## [3,] 52.34920 81.01076 ## [4,] -11.32539 -139.13169 ## [5,] 51.89335 -56.94802 ## [6,] 29.44408 -99.62837 ``` --- class: middle ### Communities ```r *my.com.fast <- walktrap.community(net) str(my.com.fast, max.level = 1) ``` ``` ## Class 'communities' hidden list of 6 ## $ merges : num [1:77186, 1:2] 58675 61627 60095 58720 58731 ... ## $ modularity: num [1:79886] 0 -0.00127 -0.00127 -0.00126 -0.00125 ... ## $ membership: num [1:79886] 1689 2004 11 169 175 ... ## $ names : chr [1:79886] "809471355116781568" "42269111" "1335618427852124163" "839520909807521793" ... ## $ vcount : int 79886 ## $ algorithm : chr "walktrap" ``` --- class: middle ## Add the layout and membership to your igraph object. ```r *V(net)$l1 <- l[,1] *V(net)$l2 <- l[,2] *V(net)$membership <- my.com.fast$membership ``` --- ## What are the largest communities? .panelset[ .panel[.panel-name[Code] ```r comunidades<- data_frame(membership=V(net)$membership) comunidades %>% count(membership) %>% ungroup() %>% mutate(total=sum(n), prop_community=n/total) %>% arrange(desc(n)) %>% top_n(5) ``` ] .panel[.panel-name[Output] ``` ## # A tibble: 5 × 2 ## membership n ## <dbl> <int> ## 1 11 18272 ## 2 4 18077 ## 3 8 7951 ## 4 13 2923 ## 5 2 1165 ``` ] ] --- ## Who are the main authorities in each community? .panelset[ .panel[.panel-name[Code] ```r # Create an datafram for the authoritiew *authorities <- data_frame(name=V(net)$name, * ind=V(net)$indegree, * membership=V(net)$membership) %>% filter(membership==11| membership==4| membership==8) %>% group_by(membership) %>% arrange(desc(ind)) %>% slice(1:10) ``` ] .panel[.panel-name[Authorities names] ```r # I will get only from the 100 most retweeted to save some time. users_most_retweets <-authorities %>% mutate(data_user=map(name, * get_user_profile)) %>% unnest() ``` ``` ## Processing from 1 to 1 ## Processing from 1 to 1 ## Processing from 1 to 1 ## Processing from 1 to 1 ## Processing from 1 to 1 ## Processing from 1 to 1 ## Processing from 1 to 1 ## Processing from 1 to 1 ## Processing from 1 to 1 ## Processing from 1 to 1 ## Processing from 1 to 1 ## Processing from 1 to 1 ## Processing from 1 to 1 ## Processing from 1 to 1 ## Processing from 1 to 1 ## Processing from 1 to 1 ## Processing from 1 to 1 ## Processing from 1 to 1 ## Processing from 1 to 1 ## Processing from 1 to 1 ## Processing from 1 to 1 ## Processing from 1 to 1 ## Processing from 1 to 1 ## Processing from 1 to 1 ## Processing from 1 to 1 ## Processing from 1 to 1 ## Processing from 1 to 1 ## Processing from 1 to 1 ## Processing from 1 to 1 ## Processing from 1 to 1 ``` ] .panel[.panel-name[Outpute] ```r # I will get only from the 100 most retweeted to save some time. users_most_retweets ``` ``` ## # A tibble: 30 × 16 ## # Groups: membership [3] ## name ind membe…¹ entit…² name1 descr…³ verif…⁴ prote…⁵ creat…⁶ id ## <chr> <dbl> <dbl> <list> <chr> <chr> <lgl> <lgl> <chr> <chr> ## 1 838099262 2480 4 <df> Patr… "" TRUE FALSE 2012-0… 8380… ## 2 1404506222… 1549 4 <df> Cent… "Acomp… FALSE FALSE 2021-0… 1404… ## 3 65720380 1451 4 <df> Glau… "Deput… TRUE FALSE 2009-0… 6572… ## 4 1330082400… 1331 4 <df> Frot… "🇧🇷Pai… TRUE FALSE 2020-1… 1330… ## 5 31139434 1245 4 <df> Glei… "Deput… TRUE FALSE 2009-0… 3113… ## 6 57771039 1201 4 <df> Rena… "Renat… TRUE FALSE 2009-0… 5777… ## 7 58288300 1065 4 <df> Gers… "Infec… TRUE FALSE 2009-0… 5828… ## 8 1097073004… 1056 4 <NULL> Pedr… "Geógr… FALSE FALSE 2019-0… 1097… ## 9 14594698 1014 4 <df> UOL … "Acomp… TRUE FALSE 2008-0… 1459… ## 10 16794066 872 4 <NULL> Blog… "Acomp… TRUE FALSE 2008-1… 1679… ## # … with 20 more rows, 7 more variables: entities$description <df[,2]>, ## # profile_image_url <chr>, location <chr>, username <chr>, url <chr>, ## # public_metrics <df[,4]>, pinned_tweet_id <chr>, and abbreviated variable ## # names ¹membership, ²entities$url$urls, ³description, ⁴verified, ⁵protected, ## # ⁶created_at ## # ℹ Use `print(n = ...)` to see more rows, and `colnames()` to see all variable names ``` ] ] --- ## Who are the main authorities in each community? .panelset[ .panel[.panel-name[ggplot code] ```r # Main Communities ggplot(users_most_retweets %>% * filter(membership=="4"), aes(x=reorder(username, ind, fill=membership), y=ind)) + geom_histogram(stat="identity", width=.5, color="black") + coord_flip() + xlab("") + ylab("") + theme_minimal(base_size = 12) + theme(plot.title = element_text(size = 22, face = "bold"), axis.title=element_text(size=16), axis.text = element_text(size=12, face="bold")) + facet_grid(~membership) ``` ] .panel[.panel-name[Community I] .center[ <img src="presentation_workshop_twitter_files/figure-html/unnamed-chunk-22-1.png" width="50%" /> ] ] .panel[.panel-name[Community II] .center[ <img src="presentation_workshop_twitter_files/figure-html/unnamed-chunk-23-1.png" width="50%" /> ] ] .panel[.panel-name[Community III] .center[ <img src="presentation_workshop_twitter_files/figure-html/unnamed-chunk-24-1.png" width="50%" /> ] ] ] --- ## Visualizing communities .panelset[ .panel[.panel-name[Function to Plot Network] ```r # A function with the density. Nice to visualize as well. my.den.plot <- function(l=l,new.color=new.color, ind=ind, legend, color){ library(KernSmooth) est <- bkde2D(l, bandwidth=c(10, 10)) plot(l,cex=log(ind+1)/4, col=new.color, pch=16, xlim=c(-160,140),ylim=c(-140,160), xlab="", ylab="", axes=FALSE) legend("topright", c(legend[1],legend[2], legend[3]), pch = 17:19, col=c(color[1], color[2], color[3])) contour(est$x1, est$x2, est$fhat, col = gray(.6), add=TRUE) } ``` ] .panel[.panel-name[Function to Plot Network] ```r # Colors for each community # Building a empty containes temp <- rep(1,length(V(net)$membership)) new.color <- "white" *new.color[V(net)$membership==11] <- "Yellow" *new.color[V(net)$membership==8] <- "pink" *new.color[V(net)$membership==4] <- "red" # Add color V(net)$new.color <- new.color ``` ] .panel[.panel-name[Network Plot] 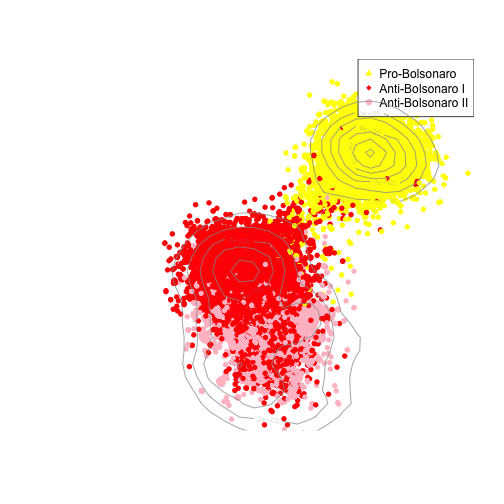<!-- --> ] ] --- ## Hashtags by communities .center[ ] .center[ <img src="figs/hashtags.png" width="100%" /> ] --- ## Sharing news on Twitter .footnote[From [News Sharing, Gatekeeping, and Polarization: A Study of the #Bolsonaro Election](https://www.tandfonline.com/doi/full/10.1080/21670811.2020.1852094)] .center[ <img src="figs/sharing_news.jpeg" width="60%" /> ] --- class:middle ## Other APIs endpoints Most of our work with the Twitter API happens with the capacity to query the API with search terms. For this reason, the search (and filter for live data collection) endpoints are the most popular. However, there are a few other endpoints from the Twitter API that can also be very useful for research puporses. Let's walk through them briefly. --- ## Getting user id Imagine a research in which you have the Twitter accounts of elites, and you want to collect their Twitter data. The first step is to collect their ids. ```r # getting some Twitter Ids *pelosi <- get_user_id("SpeakerPelosi") pelosi ``` ``` ## SpeakerPelosi ## "15764644" ``` --- ## Getting whom a user follows ```r *pelosi_network <- get_user_following(pelosi) ``` ``` ## Processing 15764644 ## Total data points: 429 ## This is the last page for 15764644 : finishing collection. ``` ```r glimpse(pelosi_network) ``` ``` ## Rows: 429 ## Columns: 14 ## $ profile_image_url <chr> "https://pbs.twimg.com/profile_images/14707589214261… ## $ created_at <chr> "2021-11-04T22:01:33.000Z", "2010-06-16T17:20:23.000… ## $ verified <lgl> TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, TRUE… ## $ description <chr> "Representative for Ohio’s Eleventh Congressional Di… ## $ protected <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FAL… ## $ id <chr> "1456381091598700556", "156333623", "937801969", "11… ## $ public_metrics <df[,4]> <data.frame[26 x 4]> ## $ pinned_tweet_id <chr> "1463532439456952323", "1422610928756043778", NA,… ## $ url <chr> "https://t.co/v695zCnmxN", "https://t.co/4xG26ktTyt"… ## $ username <chr> "RepShontelBrown", "RepAlGreen", "RepJoeGarcia", "Re… ## $ name <chr> "Rep. Shontel Brown", "Congressman Al Green", "Rep. … ## $ entities <df[,2]> <data.frame[26 x 2]> ## $ location <chr> NA, "Houston, TX & Washington, DC", "Miami, Florida"… ## $ from_id <chr> "15764644", "15764644", "15764644", "15764644", "… ``` --- ## Estimate user ideology .panelset[ .panel[.panel-name[Code] ```r #devtools::install_github("pablobarbera/twitter_ideology/pkg/tweetscores") library(tweetscores) *results <- estimateIdeology("SpeakerPelosi", pelosi_network$id, verbose = FALSE) ``` ] .panel[.panel-name[Output] .center[ ```r plot(results) ``` <img src="presentation_workshop_twitter_files/figure-html/unnamed-chunk-31-1.png" width="50%" /> ] ] ] --- ## User timeline ```r pelosi_tl = get_user_timeline(pelosi, * start_tweets = "2022-01-01T00:00:00Z", * end_tweets = "2022-10-22T00:00:00Z", n=100) #limit ``` ``` ## user: 15764644 ## Total pages queried: 1 (tweets captured this page: 100). ## Total tweets captured now reach 100 : finishing collection. ``` ```r glimpse(pelosi_tl) ``` ``` ## Rows: 100 ## Columns: 15 ## $ text <chr> "American Rescue Plan. Infrastructure Law. CHIP… ## $ possibly_sensitive <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE… ## $ source <chr> "Twitter for iPhone", "Twitter for iPhone", "Tw… ## $ edit_history_tweet_ids <list> "1582884446432563203", "1582556778608218118", … ## $ created_at <chr> "2022-10-20T00:00:35.000Z", "2022-10-19T02:18:3… ## $ id <chr> "1582884446432563203", "1582556778608218118", "… ## $ lang <chr> "en", "en", "en", "en", "en", "en", "en", "en",… ## $ public_metrics <df[,4]> <data.frame[26 x 4]> ## $ author_id <chr> "15764644", "15764644", "15764644", "1576464… ## $ entities <df[,4]> <data.frame[26 x 4]> ## $ conversation_id <chr> "1582884446432563203", "1582556778608218118", "… ## $ context_annotations <list> [<data.frame[28 x 2]>], [<data.frame[7 x 2]>… ## $ referenced_tweets <list> <NULL>, [<data.frame[1 x 2]>], <NULL>, <NULL>, … ## $ attachments <df[,1]> <data.frame[26 x 1]> ## $ in_reply_to_user_id <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, "15764644"… ``` --- ## Tweets liked by an user ```r *pelosi_likes = get_liked_tweets(pelosi) ``` ``` ## Processing 15764644 ## Total data points: 11 ## Total data points: 12 ## This is the last page for 15764644 : finishing collection. ``` ```r glimpse(pelosi_likes) # she mostly liked her own tweets ``` ``` ## Rows: 12 ## Columns: 16 ## $ text <chr> "That moment when you hear @presmccartney say the #Smith2020 speaker is @SpeakerPelosi … ## $ possibly_sensitive <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, NA ## $ source <chr> "Buffer", "Twitter Web Client", "Twitter for iPhone", "Twitter Web Client", "Twitter fo… ## $ edit_history_tweet_ids <list> "1230592378790129664", "819738961887264768", "801060499324596224", "776180205912223744"… ## $ entities <df[,4]> <data.frame[12 x 4]> ## $ created_at <chr> "2020-02-20T20:37:41.000Z", "2017-01-13T02:52:53.000Z", "2016-11-22T13:51:20.000Z", "2… ## $ id <chr> "1230592378790129664", "819738961887264768", "801060499324596224", "7761802059122237… ## $ lang <chr> "en", "en", "en", "en", "en", "en", "en", "en", "en", "en", "en", NA ## $ public_metrics <df[,4]> <data.frame[12 x 4]> ## $ author_id <chr> "17025399", "281593711", "39547629", "774337933893636096", "15174710", "82649553", "101… ## $ conversation_id <chr> "1230592378790129664", "819738961887264768", "801060499324596224", "776154162480439300"… ## $ context_annotations <list> [<data.frame[5 x 2]>], <NULL>, <NULL>, [<data.frame[1 x 2]>], <NULL>, <NULL>, [<data.fr… ## $ attachments <df[,1]> <data.frame[12 x 1]> ## $ in_reply_to_user_id <chr> NA, NA, NA, "15764644", NA, NA, NA, NA, NA, NA, NA, NA ## $ referenced_tweets <list> <NULL>, <NULL>, <NULL>, [<data.frame[1 x 2]>], <NULL>, [<data.frame[1 x 2]>], <NULL>… ## $ from_id <chr> "15764644", "15764644", "15764644", "15764644", "15764644", "15764644", "15764644", "15… ``` --- class:inverse, middle # Question? --- class:inverse, middle ## That's a wrap for Twitter data See [here](https://tiagoventura.github.io/workshop_big_data_conference/presentation_workshop_youtube.html) the link for the Youtube slides