def distance_tree(geom, geo_neigh, n):
""""
function to calculate the closest point and get their index using scipy
geom: geo pandas data frame with the reference points
geo_neigh: geo pandas data frame the neighbors location point
n: str, number of closest neighboors
"""
# convert geometries to numpy
n_geom = np.array(list(geom.geometry.apply(lambda x: (x.x, x.y))))
n_geo_neigh = np.array(list(geo_neigh.geometry.apply(lambda x: (x.x, x.y))))
# estimate the trees
btree = cKDTree(n_geo_neigh) # btreee neighbors
# captures distances and indexes
dist, idx = btree.query(n_geom, n)PPOL 5203 - Data Science I: Foundations
Week 2: Version Control, Workflow and Reproducibility: Or a bit of Git & GitHub
Professor: Tiago Ventura
Plans for Today
Best Practices for Data Science Workflow and Reproducibility
Version Control (Git and Github)
In-Class Exercise
Your first homework
Readings for the Week
The Plain Person’s Guide to Plain Text Social Science - Kieran Healy
Pro Git - Chacon & Straub
Workflow and Reproducibility
That’s what we generally look for as data scientists
But we often don’t teach students how to organize the mess behind it.
We often assume we are capable of keeping track our own work

But this assumption will set you up to fail
As you advance on your career as a data scientist:
Your projects will grow.
You will start collaborating with other colleagues (DS is fundamentally collaborative)
You will juggle through multiple project from now and from the past!
Projects will come and go.
You will re-use code A LOT!
You need to set up a system to keep track of your work
not you.
the system!
Reproducibility
Reproducibility is fundamental for any scientific project.
- If your scientific findings cannot be replicated, it is not science, and you will be in trouble.
In practice, this means your projects need to be:
fully replicated by others (that’s science)
replicable by you (that’s the practical reality)
Best Practices (the system)
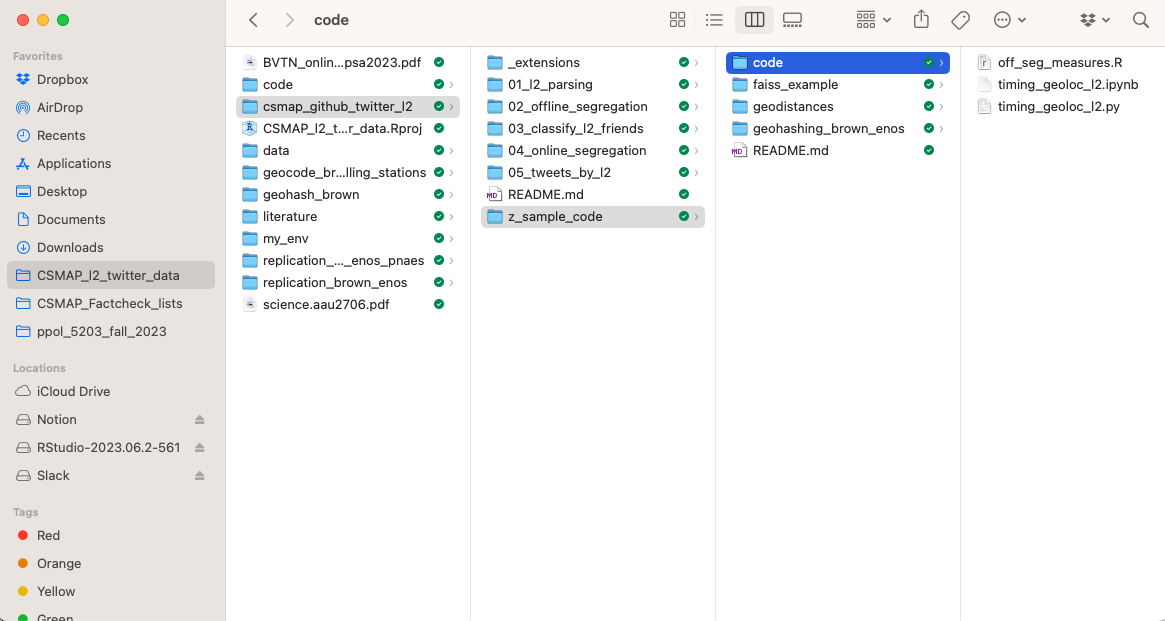
Self Contained Projects
Documentation
Readability
Naming
Portability
Version Control
Self-Contained Projects
Always consider your work in terms of projects.
A project is a self-contained unit of data science work that can be shared and replicated
A self-contained project has:
- content: data, code, outputs, literature, text
- metadata: readme for the project and each folder, information about the tools you are running
Example of Project Setup
├── /data
│ ├── /raw
│ ├── /processed
├── /docs
├── /code
| |── 01_clean_xxx.py
| |── 01_analysis_xxx.py
├── /literature
├── /output
│ ├── /tables
│ ├── /figures
├── /misc
└── readme.txt Documentation
Use # to describe every single step of your code
vs
Readability
Make you code readable in plain english. This usually mean giving names to your variables and functions that fully describe what your intents are.
Avoid:
- Abbreviation
- Generic Names
- Misleading names
- Capitalization
Naming
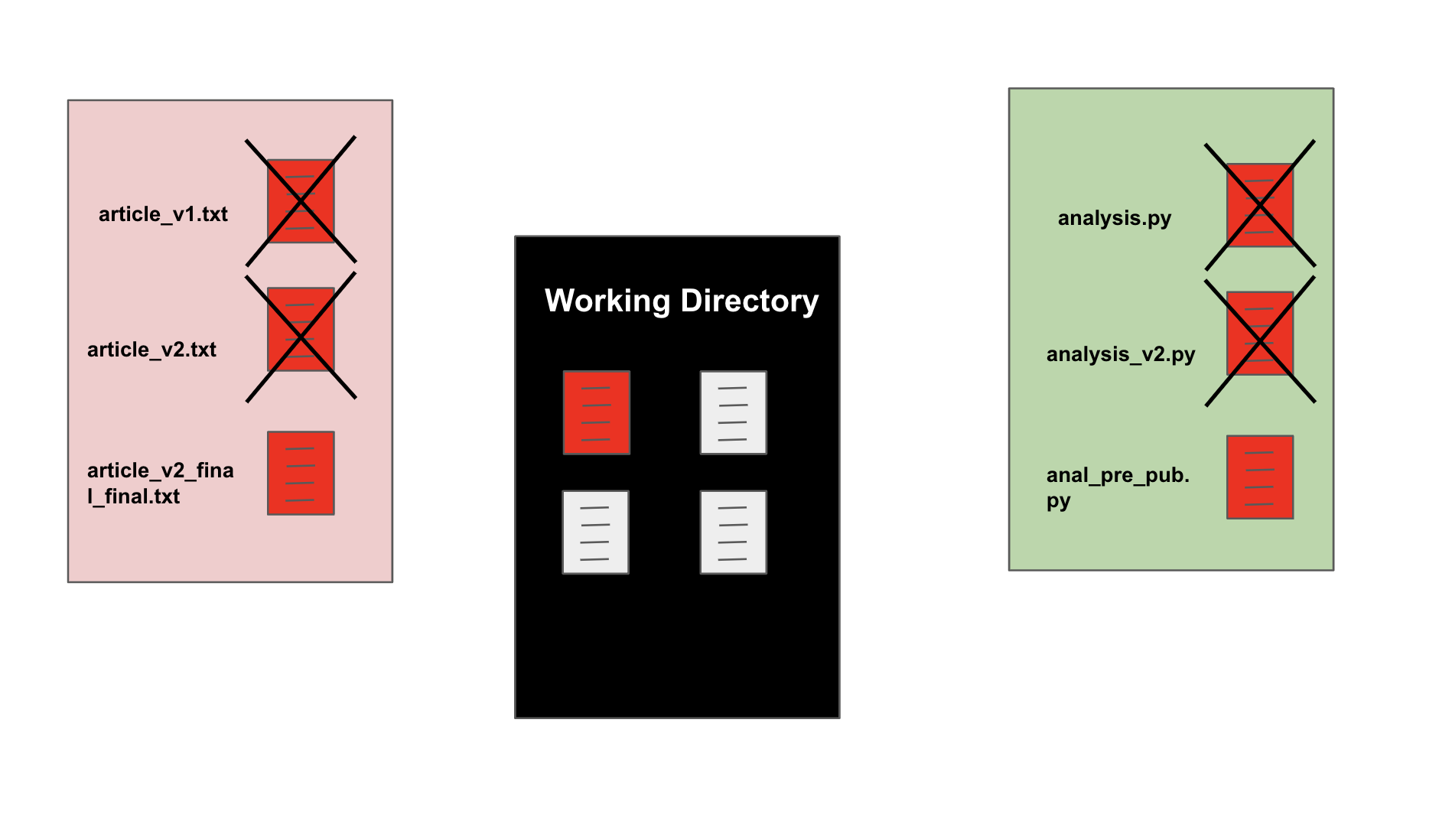
Use meaningful names for your code/data/notebooks.
File names should be meaningful
DO NOT USE SPACES. Use snake case (_) style for you files and code
Also allows you to avoid capitalization (
FileName→file_name)
data analysis 2.py→data_analysis_2.py
model_analysis.py→model_analysis_het_treatment_effects_main_paper.py
Portability
Use computational environments for your projects. (pyenv or conda)
Avoid absolute file paths
- Good Examples: “preprocessing.py” “figures/model-1.png” ” /data/survey.csv”
- Terrible examples: “/Users/me/ppol5203/data.csv” - only exists in your machine!!!
Let’ me navigate you into one of my projects.
Quiz
Take five minutes to talk to your colleague at your side. Discuss:
What you do on your day to day work that is definitely not a best practice?
What is the best practice for you code that you are most proud of?
Version Control
What is version control?
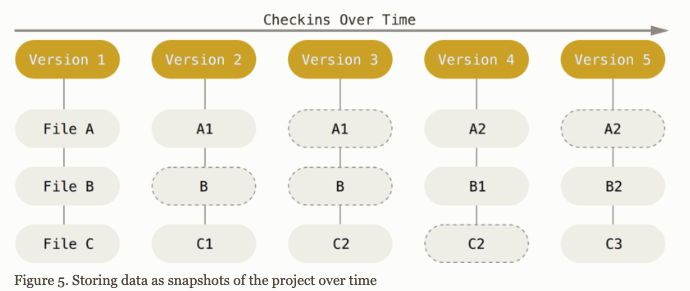
Version control is a system that records changes to a file or set of files over time so that you can recall specific versions later. (pro git)
Why version control (in theory)?

Why version control (in practice)?
Allows you to “rewind the tape” to earlier incarnations of your notes, drafts, papers and code
It is like Microsoft Word track changes but for your entire project
Easily handle collaboration (contribute to other people’s work)
Allows you to review, comment, and analyze other people’s codes
Heavily adopted in the data science community
Version Control in Theory
Key concepts we will cover:
Git and Github
Git: snapshot + distributed VCS
Three stages of git
Time travel
Remotes with Github
Git vs Github
Git: one of many options for version control in data science. Distributed system
Git: is a commandline tool. That’s why we started with commandline last week.
Github: is a public remote host for Git repositories. A web-based platform to store git repos
- It has much more features, for example, github actions, pages. We will go through some today
TLDR: you will use git locally, and share and collaborate with others using Github remotely.
- Crucial to realize those two are different!
Most common version control systems

Git: Distributed systems
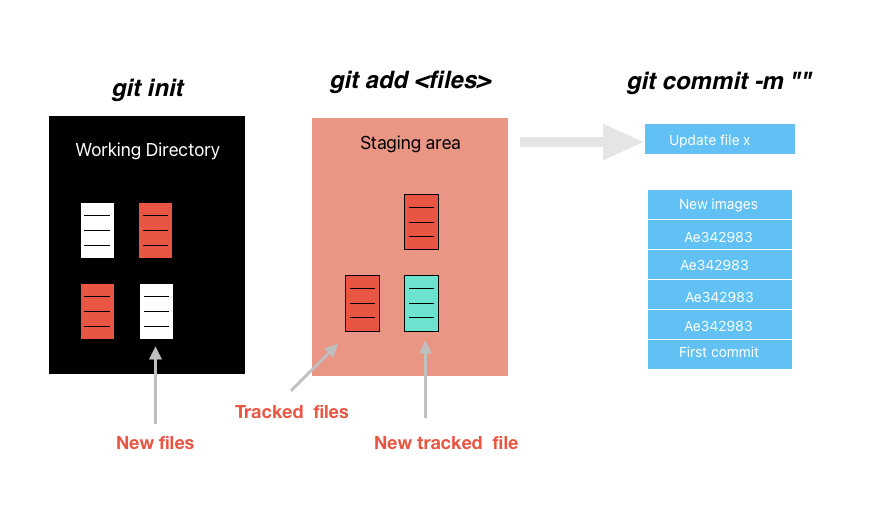
The three stages of Git
modified: local changes
stage: tell git to keep track of these files
commit: take a snapshot
Time travel in Git
Github (Remote Git Repositories)
Git in Practice
Create your first repository
Create an empty directory to be our git walkthrough
Check if you have a git
Start a repository
Tracking and staging new files: make any changes you want locally on this repo. Then stage your changes
First commit
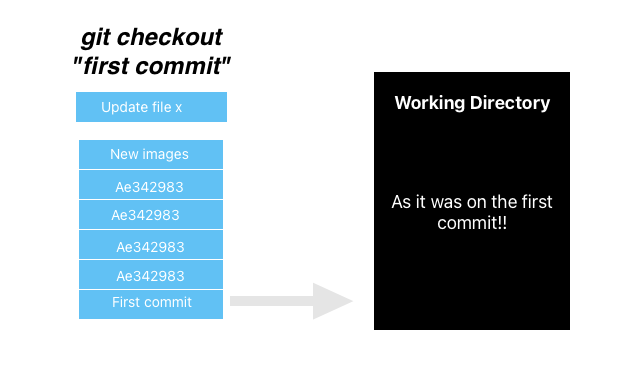
Git in Practice II: Time Travel
Returning to a previous snapshot:
Exercise.
It is time for you to practice. Try on your own, ask for help if needed. You should:
Open your commandline
Create a new folder
Initialize a git in this folder
Add some content to the folder
Stage and Commit your modify folder
Git Branching
Branching allows us to work on different paths in Git. It follows the same logic of checking out across different commits.
It is very useful for two purposes:
Experimenting with code
Collaborating with colleagues.
Basic Commands
git branch <branch-name>To create a new branchgit checkout <branch-name>To move to your new branchgit merge <branch-name>To merge your new branch into your main branch
Git Branching in Practice
Create a new branch
Write code or create new files
Stage and commit
Check status across different branches
Then we can merge our branches. Here we are doing a fast-forward merge, moving our main to keep up with the alternative branch
Visualize Git
- Visualize with Visualize Git tool
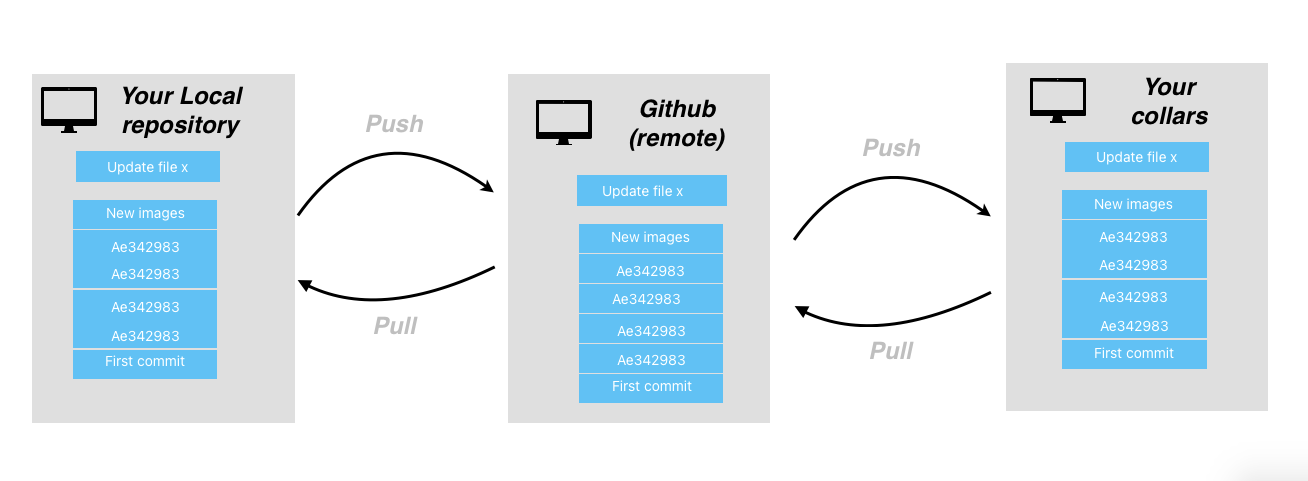
Git Remotes: Git + Github.
Most times, you will use git integrated with Github. Github allows multiple researchers to write and share code at the same time.
This is my workflow for github.
Starting a New Project. Before you write any code:
Go to your github, and create a new repository
Open your terminal, and clone the project
Track your changes:
Commit:
Push the changes in your local repository to GitHub:
Can anybody push to my repository?
No, all repositories are read-only for anonymous users. By default only the owner of the repository has write access. If you can push to your own repo, it’s because you are using one of the supported authentification methods (HTTPS, SSH, …).
If you want to grant someone else privileges to push to your repo, you would need to configure that access in the project settings.
To contribute to projects in which you don’t have push access, you push to your own copy of the repo, then ask for a pull-request. Linux is not a good example for that, because the kernel developers do not use GitHub pull requests.
Pull from Remotes
To keep up with your colleague work, you need to first pull their updates from the git repo.
See this tutorial
Git conflicts
When merging across different branches, sometimes there are conflicts between branches.
<<<<<<< HEAD
ADD EXAMPLE FROM class
=======
ADD EXAMPLE FROM CLASS
>>>>>>> new-branchOpen your text editor and navigate to the file that has merge conflicts.
Solve the conflict (which may incorporate changes from both branches) and delete the conflict markers
Stage your changes (git add)
Commit your changes (git commit)
Git in Practice: Conflicts
Create a new branch, change an file, and commit
Do the same in the main branch
Merge and solve conflict
Solve the conflict
Some additional tasks:
check the discussion about .gitignore in the lecture notes.
you might need to set up an personal token to push things on github, see here
play around with gitub: readme, directories, and issues.
Practice!
Click here to setup your github classroom and do the in-class exercise for you to practice.
- If you are connecting to GitHub for the first time, please read on Git Remotes: Git + Github on the lecture notes.
Homework.
Your homework will be posted today on slack and canvas.
- Same structure of the in-class exercise.
- Deadline: September 26, 23:59 EST.
- Questions? Come to the office hour or ask on slack.
Data science I: Foundations